======== START LECTURE #18
========
Implementing a J-type instruction, unconditional jump
opcode addr
31-26 25-0
Addr is word address; bottom 2 bits of PC are always 0
Top 4 bits of PC stay as they were (AFTER incr by 4)
Easy to add.
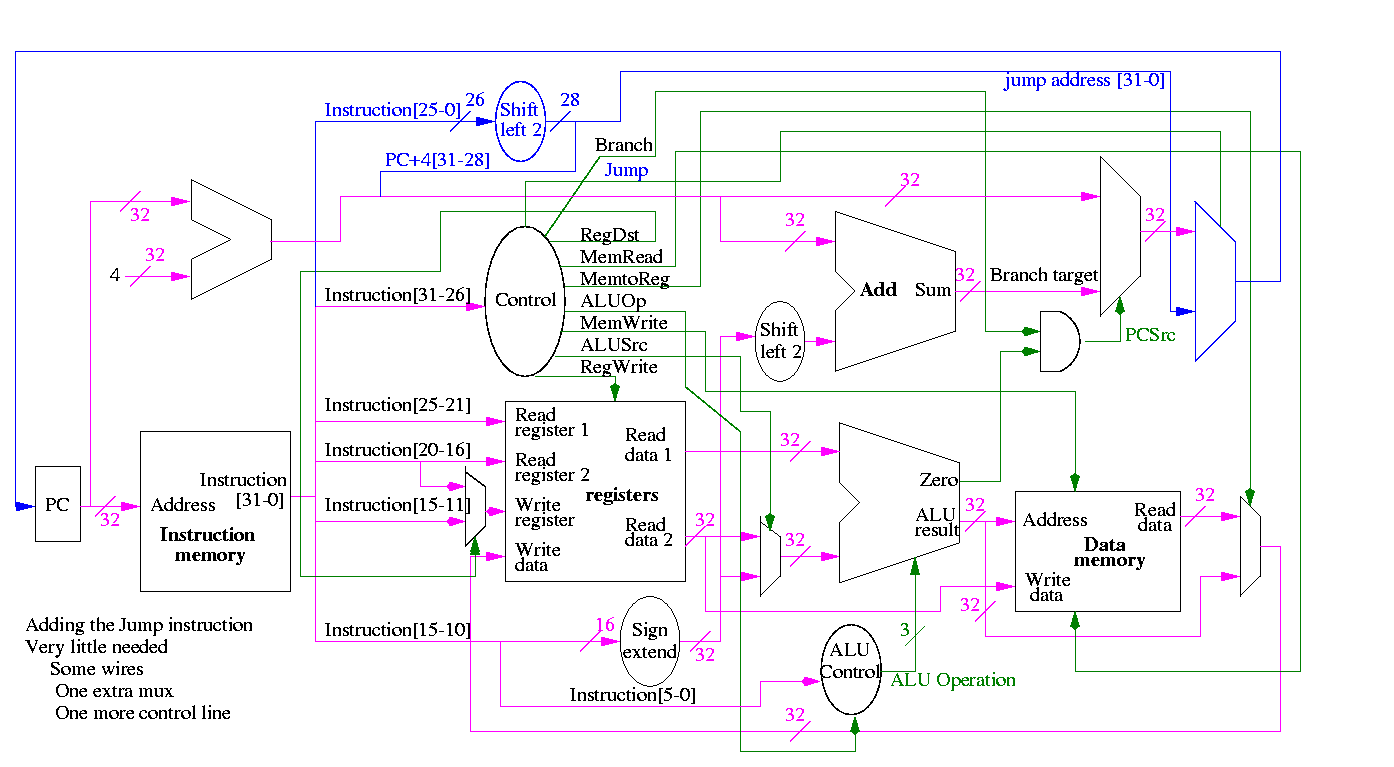
Smells like a good final exam type question.
What's Wrong
Some instructions are likely slower than others and we must set the
clock cycle time long enough for the slowest. The disparity between
the cycle times needed for different instructions is quite significant
when one considers implementing more difficult instructions, like
divide and floating point ops. Actually, if we considered cache
misses, which result in references to external DRAM, the cycle time
ratios can approach 100.
Possible solutions
-
Variable length cycle. How do we do it?
-
Asynchronous logic
-
``Self-timed'' logic.
-
No clock. Instead each signal (or group of signals) is
coupled with another signal that changes only when the first
signal (or group) is stable.
-
Hard to debug.
-
Multicycle instructions.
-
More complicated instructions have more cycles.
-
Since only one instruction is executed at a time, can reuse a
single ALU and other resourses during different cycles.
-
It is in the book right at this point but we are not covering it.
Even Faster (we are not covering this).
-
Pipeline the cycles.
-
Since at one time we will have several instructions active, each
at a different cycle, the resources can't be reused (e.g., more
than one instruction might need to do a register read/write at one
time).
-
Pipelining is more complicated than the single cycle
implementation we did.
-
This was the basic RISC technology on the 1980s.
-
A pipelined implementation of the MIPS CPU is covered in chapter 6.
-
Multiple datapaths (superscalar).
-
Issue several instructions each cycle and the hardware
figures out dependencies and only executes instructions when the
dependencies are satisfied.
-
Much more logic required, but conceptually not too difficult
providing the system executes instructions in order.
-
Pretty hairy if out of order (OOO) exectuion is
permitted.
-
Current high end processors are all OOO superscalar (and are
indeed pretty hairy).
-
VLIW (Very Long Instruction Word)
-
User (i.e., the compiler) packs several instructions into one
``superinstruction'' called a very long instruction.
-
User guarentees that there are no dependencies within a
superinstruction.
-
Hardware still needs multiple datapaths (indeed the datapaths are
not so different from superscalar).
-
The hairy control for superscalar (especially OOO superscalar)
is not needed since the dependency
checking is done by the compiler, not the hardware.
-
Was proposed and tried in 80s, but was dominated by superscalar.
-
A comeback (?) with Intel's EPIC (Explicitly Parallel Instruction
Computer) architecture.
-
Called IA-64 (Intel Architecture 64-bits); the first
implementation was called Merced and now has a funny name
(Itanium). It has recently become available.
-
It has other features as well (e.g. predication).
-
The x86, Pentium, etc are called IA-32.
Chapter 2 Performance analysis
Homework:
Read Chapter 2
2.1: Introductions
Throughput measures the number of jobs per day
that can be accomplished. Response time measures how
long an individual job takes.
- A faster machine improves both metrics (increases throughput and
decreases response time).
- Normally anything that improves response time improves throughput.
- But the reverse isn't true. For example,
adding a processor likely to increase throughput more than
it decreases response time.
-
We will be concerned primarily with response time.
We define Performance as 1 / Execution time.
So machine X is n times faster than Y means that
-
The performance of X = n * the performance of Y.
-
The execution time of X = (1/n) * the execution time of Y.
2.2: Measuring Performance
How should we measure execution time?
-
CPU time.
-
This includes the time waiting for memory.
-
It does not include the time waiting for I/O
as this process is not running and hence using no CPU time.
-
Elapsed time on an otherwise empty system.
-
Elapsed time on a ``normally loaded'' system.
-
Elapsed time on a ``heavily loaded'' system.
We use CPU time, but this does not mean the other
metrics are worse.
Cycle time vs. Clock rate.
- Recall that cycle time is the length of a cycle.
- It is a unit of time.
- For modern computers it is expressed in nanoseconds,
abbreviated ns.
- One nanosecond is one billionth of a second = 10^(-9) seconds.
- Electricity travels about 1 foot in 1ns (in normal media).
- The clock rate tells how many cycles fit into a given time unit
(normally in one second).
- So the natural unit for clock rate is cycles per second.
This used to be abbreviated CPS.
- However, the world has changed and the new name for the same
thing is Hertz, abbreviated Hz.
One Hertz is one cycle per second.
- For modern computers the rate is expressed in megahertz,
abbreviated MHz.
- One megahertz is one million hertz = 10^6 hertz.
- A few machines have a clock rate exceeding a gigahertz (GHz).
Next year many new machines will pass the gigahertz mark;
possibly some will exceed 2GHz.
- One gigahertz is one billion hertz = 10^9 hertz.
- What is the cycle time for a 700MHz computer?
- 700 million cycles = 1 second
- 7*10^8 cycles = 1 second
- 1 cycle = 1/(7*10^8) seconds = 10/7 * 10^(-9) seconds ~= 1.4ns
- What is the clock rate for a machine with a 10ns cycle time?
- 1 cycle = 10ns = 10^(-8) seconds.
- 10^8 cycles = 1 second.
- Rate is 10^8 Hertz = 100 * 10^6 Hz = 100MHz = 0.1GHz