================ Start Lecture #19
================
Notes:
- Shortcuts in windows contain more that symlinks in unix. In addition
to the file name of the original file, they can contain arguments to
pass to the file if it is executable. So a shortcut to
netscape.exe
can specify
netscape.exe //allan.ultra.nyu.edu/~gottlieb/courses/os/class-notes.html
For this reason I withdraw my objection to the name shortcut
- In answer to a question, I remarked that a hard link is a link to
a file;
whereas a symlink (or shortcut) is a link to a name.
This is a good point and I should have put it in the notes before (it
is there now).
End of Notes
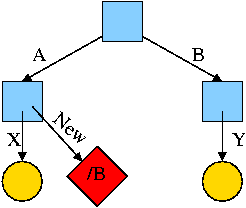
What about symlinking a directory?
cd /
mkdir /A; mkdir /B
touch /A/X; touch /B/Y
ln -s /B /A/New
Is there a file named /A/New/Y ?
Yes.
What happens if you execute cd /A/New/.. ?
- Answer: Not clear!
- Clearly you are changing directory to the parent directory of
/A/New. But is that /A or /?
- The command interpreter I use offers both possibilities.
- cd -L /A/New/.. takes you to A (L for logical).
- cd -P /A/New/.. takes you to / (P for physical).
- cd /A/New/.. takes you to A (logical is the default).
What did I mean when I said the pictures made it all clear?
Answer: From the file system perspective it is clear. Not always so
clear what programs will do.
4.3.4: Disk space management
All general purpose systems use a (non-demand) paging
algorithm for file storage. Files are broken into fixed size pieces,
called blocks that can be scattered over the disk.
Note that although this is paging, it is never called paging.
The file is completely stored on the disk, i.e., it is not
demand paging.
Actually, it is more complicated, but this is unofficial (i.e.,
will not appear on exams).
- Various optimizations are
performed to try to have consecutive blocks of a single file stored
consecutively on the disk.
- One can imagine systems that store only parts of the file on disk
with the rest on tertiary storage (some kind of tape).
- This would be just like demand paging.
- Perhaps NASA does this with their huge datasets.
- Caching (as done for example in microprocessors) is also the same
as demand paging.
- We unify these concepts in the computer architecture course.
Choice of block size
- We discussed this before when studying page size.
- Current commodity disk characteristics (not for laptops) result in
about 15ms to transfer the first byte and 10K bytes per ms for
subsequent bytes (if contiguous).
- We will explain the following terms in the I/O chapter.
- Rotation rate is 5400, 7600, or 10,000 RPM (15K just now
available).
- Recall that 6000 RPM is 100 rev/sec or one rev
per 10ms. So half a rev (the average time for to rotate to a
given point) is 5ms.
- Transfer rates around 10MB/sec = 10KB/ms.
- Seek time is around 10ms.
- This favors large blocks, 100KB or more.
- But the internal fragmentation would be severe since many files
are small.
- Typical block sizes are 4KB and 8KB.
- Unofficial
- Systems that contain multiple block sizes have been tried
(i.e., the system uses blocks of size A for some files and blocks
of size B for other files).
- Some systems use techniques to try to have consecutive blocks
of a given file near each other as well as blocks of ``related''
files (e.g., files in the same directory).
Storing free blocks
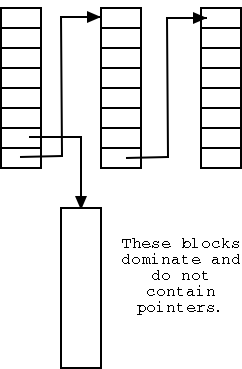
There are basically two possibilities
- An in-memory bit map.
- One bit per block
- If block size is 4KB = 32K bits, 1 bit per 32K bits
- So 32GB disk (potentially all free) needs 1MB ram.
- Variation is to demand page the bit map. This saves space
(RAM) at the cost of I/O.
- Linked list with each free block pointing to next.
- Thus you must do a read for each request.
- But reading a free block is a wasted I/O.
- Instead some free blocks contain pointers to other free
blocks. This has much less wasted I/O, but is more complicated.
- When read a block of pointers store them in memory.
- See diagram on right.
4.3.5: File System reliability
Bad blocks on disks
Not so much of a problem now. Disks are more reliable and, more
importantly, disks take care of the bad blocks themselves. That is,
there is no OS support needed to map out bad blocks. But if a block
goes bad, the data is lost (not always).
Backups
All modern systems support full and
incremental dumps.
- A level 0 dump is a called a full dump (i.e., dumps everything).
- A level n dump (n>0) is called an incremental dump and the
standard unix utility dumps
all files that have changed since the previous level n-1 dump.
- Other dump utilities dump all files that have changed since the
last level n dump.
- Keep on the disk the dates of the most recent level i dumps
for all i. In Unix this is traditionally in /etc/dumpdates.
- What about the nodump attribute?
- Default policy (for Linux at least) is to dump such files
anyway when doing a full dump, but not dump them for incremental
dumps.
- Another way to say this is the nodump attribute is honored for
level n dumps if n>1.
- The dump command has an option to override the default policy
(can specify k so that nodump is honored for level n dumps if n>k).