Operating Systems
Chapter 3: Memory Management
Also called storage management or
space management.
Memory management must deal with the storage
hierarchy present in modern machines.
- Registers, cache, central memory, disk, tape (backup)
- Move data from level to level of the hierarchy.
- How should we decide when to move data up to a higher level?
- Fetch on demand (e.g. demand paging, which is dominant now).
- Prefetch
- Read-ahead for file I/O.
- Large cache lines and pages.
- Extreme example. Entire job present whenever running.
We will see in the next few lectures that there are three independent
decision:
- Segmentation (or no segmentation)
- Paging (or no paging)
- Fetch on demand (or no fetching on demand)
Memory management implements address translation.
- Convert virtual addresses to physical addresses
- Also called logical to real address translation.
- A virtual address is the address expressed in
the program.
- A physical address is the address understood
by the computer hardware.
- The translation from virtual to physical addresses is performed by
the Memory Management Unit or (MMU).
- Another example of address translation is the conversion of
relative addresses to absolute addresses by the linker.
- The translation might be trivial (e.g., the identity) but not in a modern
general purpose OS.
- The translation might be difficult (i.e., slow).
- Often includes addition/shifts/mask--not too bad.
- Often includes memory references.
- VERY serious.
- Solution is to cache translations in a Translation
Lookaside Buffer (TLB). Sometimes called a
translation buffer (TB).
Homework: 7.
When is address translation performed?
- At compile time
- Compiler generates physical addresses.
- Requires knowledge of where the compilation unit will be
loaded.
- No linker.
- Loader is trivial.
- Primitive.
- Rarely used (MSDOS .COM files).
- At link-edit time (the ``linker lab'')
- Compiler
- Generates relocatable addresses for each compilation unit.
- References external addresses.
- Linkage editor
- Converts the relocatable addr to absolute.
- Resolves external references.
- Misnamed ld by unix.
- Also converts virtual to physical addresses by knowing where the
linked program will be loaded. Linker lab ``does'' this, but
it is trivial since we assume the linked program will be
loaded at 0.
- Loader is still trivial.
- Hardware requirements are small.
- A program can be loaded only where specified and
cannot move once loaded.
- Not used much any more.
- At load time
- Similar to at link-edit time, but do not fix
the starting address.
- Program can be loaded anywhere.
- Program can move but cannot be split.
- Need modest hardware: base/limit registers.
- Loader sets the base/limit registers.
- At execution time
- Addresses translated dynamically during execution.
- Hardware needed to perform the virtual to physical address
translation quickly.
- Currently dominates.
- Much more information later.
Extensions
- Dynamic Loading
- When executing a call, check if module is loaded.
- If not loaded, call linking loader to load it and update
tables.
- Slows down calls (indirection) unless you rewrite code
dynamically.
- Not used much.
- Dynamic Linking
- The traditional linking described above is today often called
static linking.
- With dynamic linking, frequently used routines are not linked
into the program. Instead, just a stub is linked.
- When the routine is called, the stub checks to see if the
real routine is loaded (it may have been loaded by
another program).
- If not loaded, load it.
- If already loaded, share it. This needs some OS
help so that different jobs sharing the library don't
overwrite each other's private memory.
- Advantages of dynamic linking.
- Saves space: Routine only in memory once even when used
many times.
- Bug fix to dynamically linked library fixes all applications
that use that library, without having to
relink the application.
- Disadvantages of dynamic linking.
- New bugs in dynamically linked library infect all
applications.
- Applications ``change'' even when they haven't changed.
Note: I will place ** before each memory management
scheme.
3.1: Memory management without swapping or paging
Entire process remains in memory from start to finish and does not move.
The sum of the memory requirements of all jobs in the system cannot
exceed the size of physical memory.
** 3.1.1: Monoprogramming without swapping or paging (Single User)
The ``good old days'' when everything was easy.
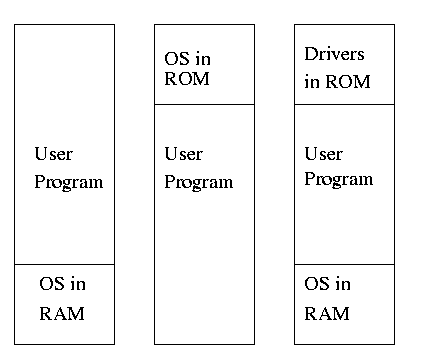
- No address translation done by the OS (i.e., address translation is
not performed dynamically during execution).
- Either reload the OS for each job (or don't have an OS, which is almost
the same), or protect the OS from the job.
- One way to protect (part of) the OS is to have it in ROM.
- Of course, must have the OS (read-write) data in ram.
- Can have a separate OS address space only accessible in
supervisor mode.
- Might just put some drivers in ROM (BIOS).
- The user employs overlays if the memory needed
by a job exceeds the size of physical memory.
- Programmer breaks program into pieces.
- A ``root'' piece is always memory resident.
- The root contains calls to load and unload various pieces.
- Programmer's responsibility to ensure that a piece is already
loaded when it is called.
- No longer used, but we couldn't have gotten to the moon in the
60s without it (I think).
- Overlays have been replaced by dynamic address translation and
other features (e.g., demand paging) that have the system support
logical address sizes greater than physical address sizes.
- Fred Brooks (leader of IBM's OS/360 project and author of ``The
mythical man month'') remarked that the OS/360 linkage editor was
terrific, especially in its support for overlays, but by the time
it came out, overlays were no longer used.
3.1.2: Multiprogramming and Memory Usage
Goal is to improve CPU utilization, by overlapping CPU and I/O
- Consider a job that is unable to compute (i.e., it is waiting for
I/O) a fraction p of the time.
- Then, with monoprogramming, the CPU utilization is 1-p.
- Note that p is often > .5 so CPU utilization is poor.
- But, if the probability that a
job is waiting for I/O is p and n jobs are in memory, then the
probability that all n are waiting for I/O is approximately p^n.
- So, with a multiprogramming level (MPL) of n,
the CPU utilization is approximately 1-p^n.
- If p=.5 and n=4, then 1-p^n = 15/16, which is much better than
1/2, which would occur for monoprogramming (n=1).
- This is a crude model, but it is correct that increasing MPL does
increase CPU utilization up to a point.
- The limitation is memory, which is why we discuss it here
instead of process management. That is, we must have many jobs
loaded at once, which means we must have enough memory for them
There are other issues as well and we will discuss them.
- Some of the CPU utilization is time spent in the OS executing
context switches so the gains are not a great as the crude model predicts.
Homework: 1, 3.
3.1.3: Multiprogramming with fixed partitions
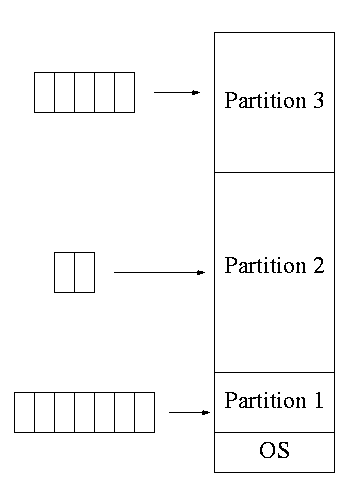
- This was used by IBM for system 360 OS/MFT (multiprogramming with a
fixed number of tasks).
- Can have a single input queue instead of one for each partition.
- So that if there are no big jobs can use big partition for
little jobs.
- But I don't think IBM did this.
- Can think of the input queue(s) as the ready list(s) with a
scheduling policy of FCFS in each partition.
- The partition boundaries are not movable (must reboot to
move a job).
- MFT can have large internal fragmentation,
i.e., wasted space inside a region
- Each process has a single ``segment'' (we will discuss segments later)
- No sharing between process.
- No dynamic address translation.
- At load time must ``establish addressability''.
- i.e. must set a base register to the location at which the
process was loaded (the bottom of the partition).
- The base register is part of the programmer visible register set.
- This is an example of address translation during load time.
- Also called relocation.
- Storage keys are adequate for protection (IBM method).
- Alternative protection method is base/limit registers.
- An advantage of base/limit is that it is easier to move a job.
- But MFT didn't move jobs so this disadvantage of storage keys is moot.
- Tanenbaum says jobs were ``run to completion''. This must be
wrong as that would mean monoprogramming.
- He probably means that jobs not swapped out and each queue is FCFS
without preemption.
================ Start Lecture #10
================
Note: Typo on lab 2.
The last input set has a process with a zero
value for IO, which is an error. Specifically, you should replace
5 (0 3 200 3) (0 9 500 3) (0 20 500 3) (100 1 100 3) (100 100 500 3)
with
5 (0 3 200 3) (0 9 500 3) (0 20 500 3) (100 1 100 3) (100 100 500 3)
End of Note.
3.2: Swapping
Moving entire processes between disk and memory is called
swapping.
3.2.1: Multiprogramming with variable partitions
- Both the number and size of the partitions change with time.
- IBM OS/MVT (multiprogramming with a varying number of tasks).
- Also early PDP-10 OS.
- Job still has only one segment (as with MFT) but now can be of any
size up to the size of the machine and can change with time.
- A single ready list.
- Job can move (might be swapped back in a different place).
- This is dynamic address translation (during run time).
- Must perform an addition on every memory reference (i.e. on every
address translation) to add the start address of the partition.
- Called a DAT (dynamic address translation) box by IBM.
- Eliminates internal fragmentation.
- Find a region the exact right size (leave a hole for the
remainder).
- Not quite true, can't get a piece with 10A755 bytes. Would
get say 10A760. But internal fragmentation is much
reduced compared to MFT. Indeed, we say that internal
fragmentation has been eliminated.
- Introduces external fragmentation, i.e., holes
outside any region.
- What do you do if no hole is big enough for the request?
- Can compactify
- Transition from bar 3 to bar 4 in diagram below.
- This is expensive.
- Not suitable for real time (MIT ping pong).
- Can swap out one process to bring in another
- Bars 5-6 and 6-7 in diagram
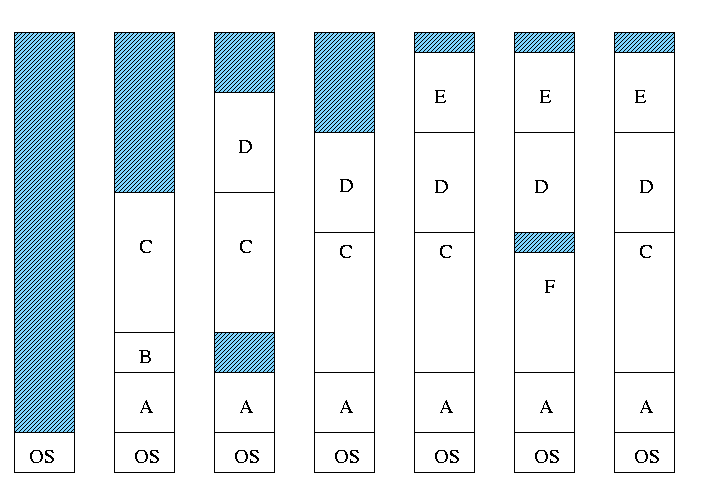
Homework: 4
- There are more processes than holes. Why?
- Because next to a process there might be a process or a hole
but next to a hole there must be a process
- So can have ``runs'' of processes but not of holes
- If after a process equally likely to have a process or a hole,
you get about twice as many processes as holes.
- Base and limit registers are used.
- Storage keys not good since compactifying would require
changing many keys.
- Storage keys might need a fine granularity to permit the
boundaries move by small amounts. Hence many keys would need to be
changed
MVT Introduces the ``Placement Question'', which hole (partition)
to choose
- Best fit, worst fit, first fit, circular first fit, quick fit, Buddy
- Best fit doesn't waste big holes, but does leave slivers and
is expensive to run.
- Worst fit avoids slivers, but eliminates all big holes so a
big job will require compaction. Even more expensive than best
fit (best fit stops if it finds a perfect fit).
- Quick fit keeps lists of some common sizes (but has other
problems, see Tanenbaum).
- Buddy system
- Round request to next highest power of two (causes
internal fragmentation).
- Look in list of blocks this size (as with quick fit).
- If list empty, go higher and split into buddies.
- When returning coalesce with buddy.
- Do splitting and coalescing recursively, i.e. keep
coalescing until can't and keep splitting until successful.
- See Tanenbaum for more details (or an algorithms book).
- A current favorite is circular first fit (also know as next fit)
- Use the first hole that is big enough (first fit) but start
looking where you left off last time.
- Doesn't waste time constantly trying to use small holes that
have failed before, but does tend to use many of the big holes,
which can be a problem.
- Buddy comes with its own implementation. How about the others?
- Bit map
- Only question is how much memory does one bit represent.
- Big: Serious internal fragmentation
- Small: Many bits to store and process
- Linked list
- Each item on list says whether Hole or Process, length,
starting location
- The items on the list are not taken from the memory to be
used by processes
- Keep in order of starting address
- Double linked
- Boundary tag
- Knuth
- Use the same memory for list items as for processes
- Don't need an entry in linked list for blocks in use, just
the avail blocks are linked
- For the blocks currently in use, just need a hole/process bit at
each end and the length. Keep this in the block itself.
- See knuth, the art of computer programming vol 1
Homework: 2, 5.
MVT Also introduces the ``Replacement Question'', which victim to
swap out
We will study this question more when we discuss
demand paging.
Considerations in choosing a victim
- Cannot replace a job that is pinned,
i.e. whose memory is tied down. For example, if Direct Memory
Access (DMA) I/O is scheduled for this process, the job is pinned
until the DMA is complete.
- Victim selection is a medium term scheduling decision
- Job that has been in a wait state for a long time is a good candidate.
- Often choose as a victim a job that has been in memory for a long
time.
- Another point is how long should it stay swapped out.
- For demand paging, where swaping out a page is not as drastic as
swapping out a job, choosing the victim is an important memory
management decision and we shall study several policies,
NOTEs:
- So far the schemes presented have had two properties:
- Each job is stored contiguously in memory. That is, the job is
contiguous in physical addresses.
- Each job cannot use more memory than exists in the system. That
is, the virtual addresses space cannot exceed the physical address
space.
- Tanenbaum now attacks the second item. I wish to do both and start
with the first.br>
- Tanenbaum (and most of the world) uses the term ``paging'' to mean
what I call demand paging. This is unfortunate as it mixes together
two concepts.
- Paging (dicing the address space) to solve the placement
problem and essentially eliminate external fragmentation.
- Demand fetching, to permit the total memory requirements of
all loaded jobs to exceed the size of physical memory.
- Tanenbaum (and most of the world) uses the term virtual memory as
a synonym for demand paging. Again I consider this unfortunate.
- Demand paging is a fine term and is quite descriptive
- Virtual memory ``should'' be used in contrast with physical
memory to describe any virtual to physical address translation.
** (non-demand) Paging
Simplest scheme to remove the requirement of contiguous physical
memory.
- Chop the program into fixed size pieces called
pages (invisible to the programmer).
- Chop the real memory into fixed size pieces called page
frames or simply frames.
- Size of a page (the page size) = size of a frame (the frame size).
- Sprinkle the pages into the frames.
- Keep a table (called the page table) having an
entry for each page. The page table entry or PTE for
page p contains the number of the frame f that contains page p.
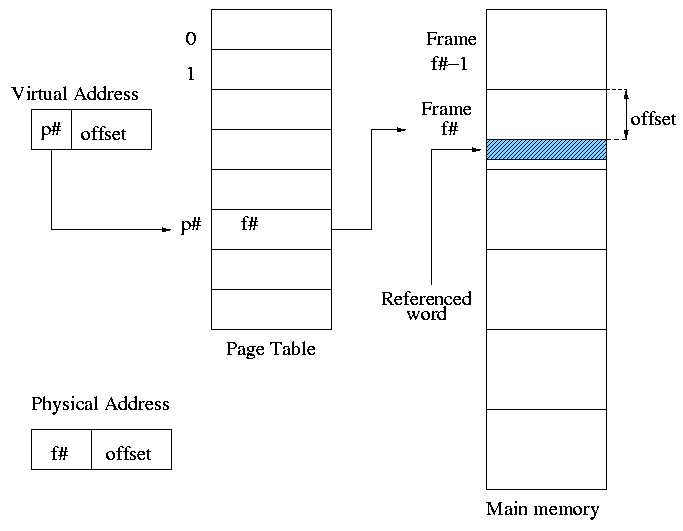
================ Start Lecture #11
================
Example: Assume a decimal machine with
page size = frame size = 1000.
Assume PTE 3 contains 459.
Then virtual address 3372 corresponds to physical address 459372.
Properties of (non-demand) paging.
- Entire job must be memory resident to run.
- No holes, i.e. no external fragmentation.
- If there are 50 frames available and the page size is 4KB than a
job requiring <= 200KB will fit, even if the available frames are
scattered over memory.
- Hence (non-demand) paging is useful.
- Introduces internal fragmentation approximately equal to 1/2 the
page size for every process (really every segment).
- Can have a job unable to run due to insufficient memory and
have some (but not enough) memory available. This is not
called external fragmentation since it is not due to memory being fragmented.
- Eliminates the placement question. All pages are equally
good since don't have external fragmentation.
- Replacement question remains.
- Since page boundaries occur at ``random'' points and can change from
run to run (the page size can change with no effect on the
program--other than performance), pages are not appropriate units of
memory to use for protection and sharing. This is discussed further
when we introduce segmentation.
Homework: 13
Address translation
- Each memory reference turns into 2 memory references
- Reference the page table
- Reference central memory
- This would be a disaster!
- Hence the MMU caches page#-->frame# translations. This cache is kept
near the processor and can be accessed rapidly.
- This cache is called a translation lookaside buffer (TLB) or
translation buffer (TB).
- For the above example, after referencing virtual address 3372,
entry 3 in the TLB would contain 459.
- Hence a subsequent access to virtual address 3881 would be
translated to physical address 459881 without a memory reference.
Choice of page size is discuss below.
Homework: 8.
3.3: Virtual Memory (meaning fetch on demand)
Idea is that a program can execute even if only the active portion of its
address space is memory resident. That is, swap in and swap out
portions of a program. In a crude sense this can be called
``automatic overlays''.
Advantages
- Can run a program larger than the total physical memory.
- Can increase the multiprogramming level since the total size of
the active, i.e. loaded, programs (running + ready + blocked) can
exceed the size of the physical memory.
- Since some portions of a program are rarely if ever used, it is
an inefficient use of memory to have them loaded all the time. Fetch on
demand will not load them if not used and will unload them during
replacement if they are not used for a long time (hopefully).
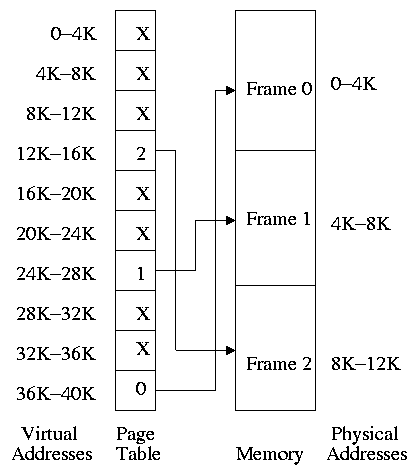
3.2.1: Paging (meaning demand paging)
Fetch pages from disk to memory when they are referenced, with a hope
of getting the most actively used pages in memory.
- Very common: dominates modern operating systems
- Started by the Atlas system at Manchester University in the 60s
(Fortheringham).
- Each PTE continues to have the frame number if the page is
loaded.
- But what if the page is not loaded (exists only on disk)?
- The PTE has a flag indicating if it is loaded (can think of
the X in the diagram on the right as indicating that this flag is
not set).
- If not loaded, the location on disk could be kept in the PTE
(not shown in the diagram). But normally it is not
(discussed below).
- When a reference is made to a non-loaded page (sometimes
called a non-existent page, but that is a bad name), the system
has a lot of work to do. We give more details
below.
- Choose a free frame if one exists
- If not
- Choose a victim frame.
- More later on how to choose a victim.
- Called the replacement question
- Write victim back to disk if dirty,
- Update the victim PTE to show that it is not loaded
and where on disk it has been put (perhaps the disk
location is already there).
- Copy the referenced page from disk to the free frame.
- Update the PTE of the referenced page to show that it is
loaded and give the frame number.
- Do the standard paging address translation (p#,off)-->(f#,off).
- Really not done quite this way
- There is ``always'' a free frame because ...
- There is a deamon active that checks the number of free frames
and if this is too low, chooses victims and ``pages them out''
(writing them back to disk if dirty).
- Choice of page size is discussed below.
Homework: 11.
3.3.2: Page tables
A discussion of page tables is also appropriate for (non-demand)
paging, but the issues are more acute with demand paging since the
tables can be much larger. Why?
- The total size of the active processes is no longer limited to
the size of physical memory. Since the total size of the processes is
greater, the total size of the page tables is greater and hence
concerns over the size of the page table are more acute.
- With demand paging an important question is the choice of a victim
page to page out. Data in the page table
can be useful in this choice.
We must be able access to the page table very quickly since it is
needed for every memory access.
Unfortunate laws of hardware.
- Big and fast are essentially incompatible.
- Big and fast and low cost is hopeless.
So we can't just say, put the page table in fast processor registers,
and let it be huge, and sell the system for $1500.
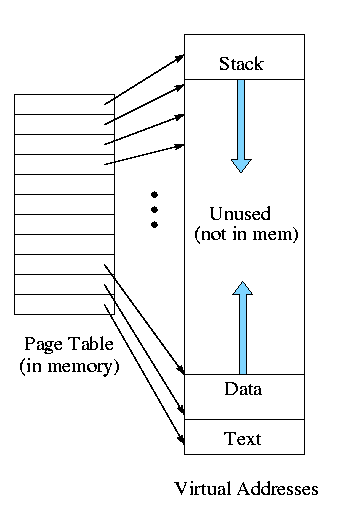
For now, put the (one-level) page table in main memory.
- Seems too slow since all memory references require two reference.
- TLB very helpful to reduce the average delay as mentioned above
(discussed later in more detail).
- It might be too big.
- Currently we are considering contiguous virtual
addresses ranges (i.e. the virtual addresses have no holes).
- Typically put the stack at one end of virtual address and the
global (or static) data at the other end and let them grow towards
each other
- The memory in between is unused.
- This unused memory can be huge (in address range) and hence
the page table will mostly contain unneeded PTEs
- Works fine if the maximum virtual address size is small, which
was once true (e.g., the PDP-11 as discussed by Tanenbaum) but is no
longer the case.
Contents of a PTE
Each page has a corresponding page table entry (PTE). The
information in a PTE is for use by the hardware. Information set by
and used by the OS is normally kept in other OS tables. The page
table format is determined by the hardware so access routines are not
portable. The following fields are often present.
- The valid bit. This tells if
the page is currently loaded (i.e., is in a frame). If set, the frame
pointer is valid. It is also called the presence or
presence/absence bit. If a page is accessed with the valid
bit zero, a page fault is generated by the hardware.
- The frame number. This is the main reason for the table. It is
needed for virtual to physical address translation.
- TheModified bit. Indicates that some part of the page
has been written since it was loaded. This is needed when the page is
evicted so the OS can know that the page must be written back to disk.
- The referenced bit. Indicates that some word in the page
has been referenced. Used to select a victim: unreferenced pages make
good victims by the locality property.
- Protection bits. For example one can mark text pages as
execute only. This requires that boundaries between regions with
different protection are on page boundaries. Normally many
consecutive (in logical address) pages have the same protection so
many page protection bits are redundant.
Protection is more
naturally done with segmentation.
Multilevel page tables (not on 202 exams)
Recall the previous diagram. Most of the virtual memory is the
unused space between the data and stack regions. However, with demand
paging this space does not waste real memory. But the single
large page table does waste real memory.
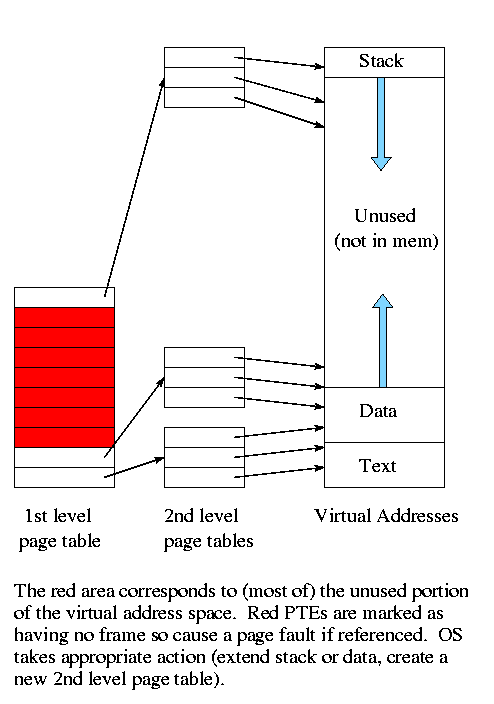
The idea of multi-level page tables (a similar idea is used in Unix
inode-based file systems) is to add a level of indirection and have a
page table containing pointers to page tables.
- Imagine one big page table.
- Call it the second level page table and
cut it into pieces each the size of a page.
Note that you can get many PTEs in one page so you will have far
fewer of these pages than PTEs
- Now construct a first level page table containing PTEs that point to
these pages.
- This first level PT is small enough to store in memory.
- But since we still have the 2nd level PT, we have made the world
bigger not smaller!
- Don't store in memory those 2nd level page tables all of whose PTEs
refer to unused memory. That is use demand paging on the (second
level) page table
Do an example on the board
The VAX used a 2-level page table structure, but with some wrinkles
(see Tanenbaum for details).
Naturally, there is no need to stop at 2 levels. In fact the SPARC
has 3 levels and the Motorola 68030 has 4 (and the number of bits of
Virtual Address used for P#1, P#2, P#3, and P#4 can be varied).
3.3.4: Associative memory (TLBs)
Note:
Tanenbaum suggests that ``associative memory'' and ``translation
lookaside buffer'' are synonyms. This is wrong. Associative memory
is a general structure and translation lookaside buffer is a special
case.
An
associative memory is a content addressable
memory. That is you access the memory by giving the value
of some field and the hardware searches all the records and returns
the record whose field contains the requested value.
For example
Name | Animal | Mood | Color
======+========+==========+======
Moris | Cat | Finicky | Grey
Fido | Dog | Friendly | Black
Izzy | Iguana | Quiet | Brown
Bud | Frog | Smashed | Green
If the index field is Animal and Iguana is given, the associative
memory returns
Izzy | Iguana | Quiet | Brown
A Translation Lookaside Buffer
or TLB
is an associate memory
where the index field is the page number. The other fields include
the frame number, dirty bit, valid bit, and others.
-
A TLB is small and expensive but at least it is
fast. When the page number is in the TLB, the frame number
is returned very quickly.
-
On a miss, the page number is looked up in the page table. The record
found is placed in the TLB and a victim is discarded. There is no
placement question since all entries are accessed at the same time.
But there is a replacement question.
Homework: 15.
3.3.5: Inverted page tables
Keep a table indexed by frame number with the entry f containing the
number of the page currently loaded in frame f.
- Since modern machine have a smaller physical address space than
virtual address space, the table is smaller
- But on a TLB miss, must search the inverted page table.
- Would be hopelessly slow except that some tricks are employed.
- The book mentions some but not all of the tricks, we are skipping
this topic.
3.4: Page Replacement Algorithms
These are solutions to the replacement question.
Good solutions take advantage of locality.
- Temporal locality: If a word is referenced now,
it is likely to be referenced in the near future.
- This argues for caching referenced words,
i.e. keeping the referenced word near the processor for a while.
- Spatial locality: If a word is referenced now,
nearby words are likely to be referenced in the near future.
- This argues for prefetching words around the currently
referenced word.
- These are lumped together into locality: If any
word in a page is referenced, each word in the page is ``likely'' to
be referenced.
- So it is good to bring in the entire page on a miss and to
keep the page in memory for a while.
-
When programs begin there is no history so nothing to base
locality on. At this point the paging system is said to be undergoing
a ``cold start''.
-
Programs exhibit ``phase changes'', when the set of pages referenced
changes abruptly (similar to a cold start). At the point of a phase
change, many page faults occur because locality is poor.
Pages belonging to processes that have terminated are of course
perfect choices for victims.
Pages belonging to processes that have been blocked for a long time
are good choices as well.
Random
A lower bound on performance. Any decent scheme should do better.
3.4.1: The optimal page replacement algorithm (opt PRA) (aka
Belady's min PRA)
Replace the page whose next
reference will be furthest in the future.
- Also called Belady's min algorithm.
- Provably optimal. That is, generates the fewest number of page
faults.
- Unimplementable: Requires predicting the future.
- Good upper bound on performance.
================ Start Lecture #12
================
3.4.2: The not recently used (NRU) PRA
Divide the frames into four classes and make a random selection from
the lowest nonempty class.
- Not referenced, not modified
- Not referenced, modified
- Referenced, not modified
- Referenced, modified
Assumes that in each PTE there are two extra flags R (sometimes called
U, for used) and M (often called D, for dirty).
Also assumes that a page in a lower priority class is cheaper to evict.
- If not referenced, probably not referenced again soon so not so
important.
- If not modified, do not have to write it out so the cost of the
eviction is lower.
-
When a page is brought in, OS resets R and M (i.e. R=M=0)
-
On a read, hardware sets R.
-
On a write, hardware sets R and M.
We again have the prisoner problem, we do a good job of making little
ones out of big ones, but not the reverse. Need more resets.
Every k clock ticks, reset all R bits
- Why not reset M?
Answer: Must have M accurate to know if victim needs to be written back
- Could have two M bits one accurate and one reset, but I don't know
of any system (or proposal) that does so.
What if the hardware doesn't set these bits?
-
OS can use tricks
-
When the bits are reset, make the PTE indicate the page is not
resident (i.e. lie). On the page fault, set the appropriate bit(s).
3..4.3: FIFO PRA
Simple but poor since usage of the page is ignored.
Belady's Anomaly: Can have more frames yet generate
more faults.
Example given later.
3.4.4: Second chance PRA
Similar to the FIFO PRA but when time choosing a victim, if the page
at the head of the queue has been referenced (R bit set), don't evict
it.
Instead reset R and move the page to the rear of the queue (so it
looks new).
The page is being a second chance.
What if all frames have been referenced?
Becomes the same as fifo (but takes longer).
Might want to turn off the R bit more often (say every k clock ticks).
3.4.5: Clock PRA
Same algorithm as 2nd chance, but a better (and I would say obvious)
implementation: Use a circular list.
Do an example.
LIFO PRA
This is terrible! Why?
Ans: All but the last frame are frozen once loaded so you can replace
only one frame. This is especially bad after a phase shift in the
program when it is using all new pages.
3.4.6:Least Recently Used (LRU) PRA
When a page fault occurs, choose as victim that page that has been
unused for the longest time, i.e. that has been least recently used.
LRU is definitely
- Implementable: The past is knowable.
- Good: Simulation studies have shown this.
- Difficult. Essentially need to either:
- Keep a time stamp in each PTE, updated on each reference
and scan all the PTEs when choosing a victim to find the PTE
with the oldest timestamp.
- Keep the PTEs in a linked list in usage order, which means
on each reference moving the PTE to the end of the list
Homework: 19, 20
A hardware cutsie in Tanenbaum
- For n pages, keep an nxn bit matrix.
- On a reference to page i, set row i to all 1s and col i to all 0s
-
At any time the 1 bits in the rows are ordered by inclusion. I.e. one
row's 1s are a subset of another row's 1s, which is a subset of a
third. (Tanenbaum forgets to mention this.)
-
So the row with the fewest 1s is a subset of all the others and is
hence least recently used
- Cute, but still impractical.
3.4.7: Approximating LRU in Software
The Not Frequently Used (NFU) PRA
- Include a counter in each PTE (and have R in each PTE).
- Set counter to zero when page is brought into memory.
- For each PTE, every k clock ticks.
- Add R to counter.
- Clear R.
- Choose as victim the PTE with lowest count.
The Aging PRA
NFU doesn't distinguish between old references and recent one. The
following modification does distinguish.
- Include a counter in each PTE (and have R in each PTE).
- Set counter to zero when page is brought into memory.
- For each PTE, every k clock ticks.
- Shift counter right one bit.
- Insert R as new high order bit (HOB).
- Clear R.
- Choose as victim the PTE with lowest count.
| R | counter |
|---|
| 1 | 10000000 |
|
| 0 | 01000000 |
|
| 1 | 10100000 |
|
| 1 | 11010000 |
|
| 0 | 01101000 |
|
| 0 | 00110100 |
|
| 1 | 10011010 |
|
| 1 | 11001101 |
|
| 0 | 01100110 |
|
Homework: 21, 25
3.5: Modeling Paging Algorithms
3.5.1: Belady's anomaly
Consider a system that has no pages loaded and that uses the FIFO
PRU.
Consider the following ``reference string'' (sequences of pages referenced).
0 1 2 3 0 1 4 0 1 2 3 4
If we have 3 frames this generates 9 page faults (do it).
If we have 4 frames this generates 10 page faults (do it).
Theory has been developed and certain PRA (so called ``stack
algorithms'') cannot suffer this anomaly for any reference string.
FIFO is clearly not a stack algorithm. LRU is.
Repeat the above calculations for LRU.
3.6: Design issues for (demand) Paging
3.6.1 & 3.6.2: The Working Set Model and Local vs Global Policies
I will do these in the reverse order (which makes more sense). Also
Tanenbaum doesn't actually define the working set model, but I shall.
A local PRA is one is which a victim page is chosen
among the pages of the same process that requires a new page. That is
the number of pages for each process is fixed. So LRU means the page
least recently used by this process.
- Of course we can't have a purely local policy, why?
Answer: A new process has no pages and even if we didn't apply this for
the first page loaded, the process would remain with only one page.
- Perhaps wait until a process has been running a while.
- A global policy is one in which the choice of
victim is made among all pages of all processes.
If we apply global LRU indiscriminately with some sort of RR processor
scheduling policy, and memory is somewhat over-committed, then by the
time we get around to a process, all the others have run and have
probably paged out this process.
If this happens each process will need to page fault at a high
rate; this is called thrashing.
It is therefore important to get a good
idea of how many pages a process needs, so that we can balance the
local and global desires.
The working set policy (Peter Denning)
The goal is to specify which pages a given process needs to have
memory resident in order for the give process to run without too many
page faults.
- But this is impossible since it requires predicting the future.
- So we make the assumption that the immediate future is well
approximated by the immediate past.
-
Measure time in units of memory references, so t=1045 means the time
when the 1045th memory reference is issued.
- In fact we measure time separately
for each process, so t=1045 really means the time when this process
made its 1045th memory reference.
-
W(t,&omega) is the set of pages referenced (by the given process) from
time t-ω to time t.
- That is, W(t,ω) is the set pages referenced during
the window of size ω ending at time t.
- That is, W(t,ω) is the set of pages referenced by the last
ω memory references ending at reference t.
- W(t,ω) is called the working set at time t
(with window ω).
- Netscape doesn't (yet) support ω to give the Greek letter.
Ouch
-
w(t,ω) is the size of the set W(t,ω), i.e. is the
number of pages referenced in the window.
The idea of the working set policy is to ensure that each process
keeps its working set in memory.
- One possibility is to allocate w(t,ω) frames to each process
(this number differs for each process and changes with time) and then
use a local policy.
- What if there aren't enough frames to do this?
- Ans: Reduce the multiprogramming level (MPL)! That is, we have a
connection between memory management and process management. This is
the suspend/resume arcs we saw way back when.
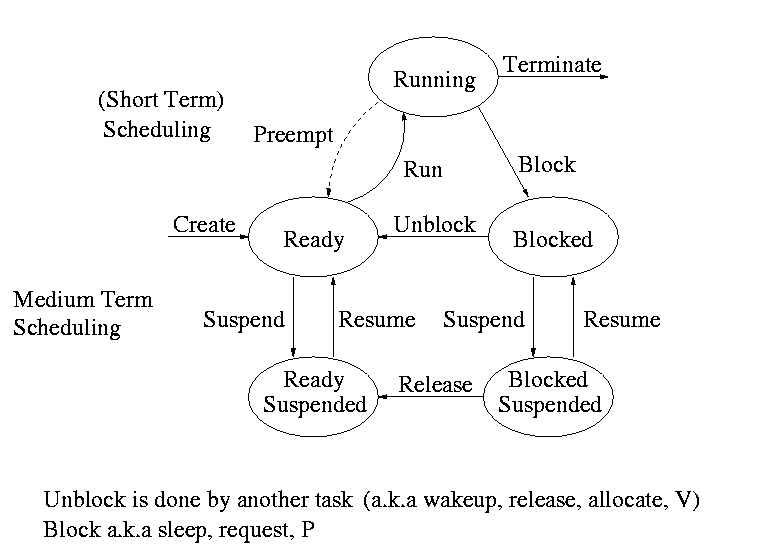
Interesting questions include:
- What value should be used for ω?
Experiments have been done and ω is surprisingly robust (i.e.,
for a given system a fixed value works reasonably for a wide variety
of job mixes)
- How should we calculate W(t,ω)?
Hard so do exactly so ...
... various approximations to the working set, have been devised.
- Wsclock
- Use the aging algorithm above to maintain a counter for
each PTE and declare a page whose counter is above a certain threshold
to be part of the working set.
- Apply the clock algorithm globally (i.e. to all pages) but
refuse to page out any page in a working set, the resulting algorithm
is called wsclock.
- What if we find there are no pages we can page out?
Answer: Reduce the MPL.
- Page Fault Frequency (PFF)
- For each process keep track of the page fault frequency, which
is the number of faults divided by the number of references.
- Actually, must use a window or a weighted calculation since
you are really interested in the recent page fault frequency.
- If the PFF is too high, allocate more frames to this process.
Either
- Raise its number of frames and use local policy; or
- Bar its frames from eviction (for a while) and use a
global policy.
- What if there are not enough frames?
Answer: Reduce the MPL.
================ Start Lecture #13
================
3.6.3: Page size
- Page size ``must'' be a multiple of the disk block size. Why?
Answer: When copying out a page if you have a partial disk block, you
must do a read/modify/write (i.e., 2 I/Os).
- Important property of I/O that we will learn later this term is
that eight I/Os each 1KB takes considerably longer than one 8KB I/O
- Characteristics of a large page size.
- Good for user I/O.
- If I/O done using physical addresses, then I/O crossing a
page boundary is not contiguous and hence requires multiple
I/Os
- If I/O uses virtual addresses, then page size doesn't effect
this aspect of I/O. That is the addresses are contiguous in virtual
address and hence one I/O is done.
- Good for demand paging I/O.
- Better to swap in/out one big page than several small
pages.
- But if page is too big you will be swapping in data that is
really not local and hence might well not be used.
- Large internal fragmentation (1/2 page size).
- Small page table.
- A very larg page size leads to very few pages. Process will
have many faults if using demand
paging and the process frequently references more regions than
frames.
- A mall page size has the opposite characteristics.
3.6.4: Implementation Issues
Don't worry about instruction backup. Very machine dependent and
modern implementations tend to get it right.
Locking (pinning) pages
We discussed pinning jobs already. The
same (mostly I/O) considerations apply to pages.
Shared pages
Really should share segments.
- Must keep reference counts or something so that when a process
terminates, pages (even dirty pages) it shares with another process
are not automatically discarded.
- Similarly, a reference count would make a widely shared page (correctly)
look like a poor choice for a victim.
- A good place to store the reference count would be in a structure
pointed to by both PTEs. If stored in the PTEs, must keep them
consistent between processes.
Backing Store
The issue is where on disk do we put pages.
- For program text, which is presumably read only, a good choice is
the file itself.
- What if we decide to keep the data and stack each contiguous on
the backing store.
Data and stack grow so must be prepared to grow the space on
disk and leads to the same issues and problems as we saw with MVT.
- If those issues/problems are painful, we can scatter the pages on
the disk.
- That is we employ paging!
- This is NOT demand paging.
- Need a table to say where the backing space for each page is
located.
- This corresponds to the page table used to tell where in
real memory a page is located.
- The format of the ``memory page table'' is determined by
the hardware since the hardware modifies/accesses it.
- The format of the ``disk page table'' is decided by the OS
designers and is machine independent.
- If the format of the memory page table was flexible, then
we might well keep the disk information in it as well.
Paging Daemons
Done earlier
Page Fault Handling (Not on the 202 exams)
What happens when a process, say process A, gets a page fault?
- The hardware detects the fault and traps to the kernel (switches
to supervisor mode and saves state).
- Some assembly language code save more state, establishes the
C-language (or another programming language) environment, and
``calls'' the OS.
- The OS determines that a page fault occurred and which page was
referenced.
- If the virtual address is invalid, process A is killed.
If the virtual address is valid, the OS must find a free frame.
If there is no free frames, the OS selects a victim frame.
Call the process owning the victim frame, process B.
(If the page replacement algorithm is local process B is process A.)
- If the victim frame is dirty, the OS schedules an I/O write to
copy the frame to disk.
Thus, if the victim frame is dirty, process B is
blocked (it might already be blocked for some other reason).
Process A is also blocked since it needs to wait for this frame to be free.
The process scheduler is invoked to perform a context switch.
- Tanenbaum ``forgot'' some here.
- The process selected by the scheduler (say process C) runs.
- Perhaps C is preempted for D or perhaps C blocks and D runs
and then perhaps D is blocked and E runs, etc.
- When the I/O to write the victim frame completes, a Disk
interrupt occurs. Assume processes C is running at the time.
- Hardware trap / assembly code / OS determines I/O done.
- Processes B is moved from blocked to ready
(unless B is also blocked for some other reason).
- The scheduler picks a process to run, maybe A, maybe B, maybe
C, maybe another processes.
- At some point the scheduler does pick process A to run.
Recall that at this point A is still executing OS code.
- Now the O/S has a clean frame (this may be much later in wall clock
time if a victim frame had to be written).
The O/S schedules an I/O to read the desired page into this clean
frame.
Process A is blocked (perhaps for the second time) and hence the
process scheduler is invoked to perform a context switch.
- A Disk interrupt occurs when the I/O completes (trap / asm / OS
determines I/O done). The PTE is updated.
- The O/S may need to fix up process A (e.g. reset the program
counter to re-execute the instruction that caused the page fault).
- Process A is placed on the ready list and eventually is chosen by
the scheduler to run.
Recall that process A is executing O/S code.
- The OS returns to the first assembly language routine.
- The assembly language routine restores registers, etc. and
``returns'' to user mode.
Process A is unaware that all this happened.
3.7: Segmentation
Up to now, the virtual address space has been contiguous.
- Among other issues this makes memory management difficult when
there are more that two dynamically growing regions.
- With two regions you start them on opposite sides of the virtual
space as we did before.
- Better is to have many virtual address spaces each starting at
zero.
- This split up is user visible.
- Without segmentation (equivalently said with just one segment) all
procedures are packed together so if one changes in size all the virtual
addresses following are changed and the program must be re-linked.
- Eases flexible protection and sharing (share a segment). For
example, can have a shared library.
Homework: 29.
** Two Segments
Late PDP-10s and TOPS-10
- One shared text segment, that can also contain shared
(normally read only) data.
- One (private) writable data segment.
- Permission bits on each segment.
- Which kind of segment is better to evict?
- Swap out shared segment hurts many tasks.
- The shared segment is read only (probably) so no writeback
is needed.
- ``One segment'' is OS/MVT done above.
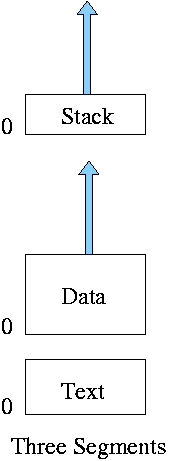
** Three Segments
Traditional Unix shown at right.
- Shared text marked execute only.
- Data segment (global and static variables).
- Stack segment (automatic variables).
** Four Segments
Just kidding.
** General (not necessarily demand) Segmentation
- Permits fine grained sharing and protection.
- Visible division of program.
- Variable size segments.
- Address = (seg#, offset).
- Does not mandate how stored in memory.
- One possibility is that the entire program must be in memory
in order to run it.
Use whole process swapping.
Very early versions of Unix did this.
- Can also implement demand segmentation.
- Can combine with demand paging (done below).
- Requires a segment table with a base and limit value for each
segment.
Similar to a page table.
- Entries are called STEs, Segment Table Entries.
- (seg#, offset) --> if (offset<limit) base+offset else error.
- Segmentation exhibits external fragmentation, just as whole program
swapping.
Since segments are smaller than programs (several segments make up one
program), the external fragmentation is not as bad.
** Demand Segmentation
Same idea as demand paging applied to segments.
- If a segment is loaded, base and limit are stored in the STE and
the valid bit is set in the PTE.
- The PTE is accessed for each memory reference (not really, TLB).
- If the segment is not loaded, the valid bit is unset.
The base and limit as well as the disk
address of the segment is stored in the an OS table.
- A reference to a non-loaded segment generate a segment fault
(analogous to page fault).
- To load a segment, we must solve both the placement question and the
replacement question (for demand paging, there is no placement question).
- I believe demand segmentation was once implemented but am not
sure.
It is not used in modern systems.
The following table mostly from Tanenbaum compares demand
paging with demand segmentation.
| Consideration |
Demand
Paging | Demand
Segmentation |
|---|
| Programmer aware |
No | Yes |
| How many addr spaces |
1 | Many |
| VA size > PA size |
Yes | Yes |
Protect individual
procedures separately |
No | Yes |
Accommodate elements
with changing sizes |
No | Yes |
| Ease user sharing |
No | Yes |
| Why invented |
let the VA size
exceed the PA size |
Sharing, Protection,
independent addr spaces |
|
| Internal fragmentation |
Yes | No, in principle |
| External fragmentation |
No | Yes |
| Placement question |
No | Yes |
| Replacement question |
Yes | Yes |
** 3.7.2: Segmentation with paging
Combines both segmentation and paging to get advantages of both at
a cost in complexity. This is very common now.
- A virtual address becomes a triple: (seg#, page#, offset).
- Each segment table entry (STE) points to the page table for that
segment.
Compare this with a
multilevel page table.
- The size of each segment is a multiple of the page size (since the
segment consists of pages). Perhaps not. Can keep the exact size in
the STE (limit value) and shoot the process if it referenced beyond
the limit. In this case the last page of each segment is partially valid.
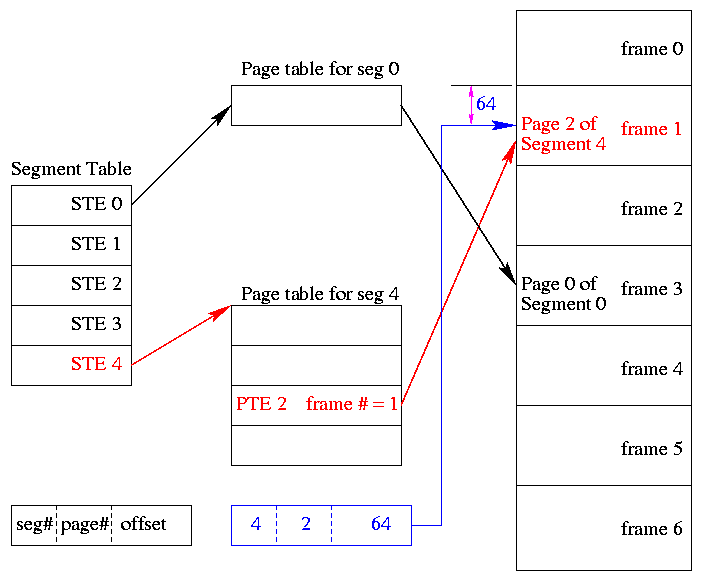
- The page# field in the address gives the entry in the chosen page
table and the offset gives the offset in the page.
- From the limit field, one can easily compute the size of the
segment in pages (which equals the size of the corresponding page
table in PTEs). Implementations may require the size of a segment to
be a multiple of the page size in which case the STE would store the
number of pages in the segment.
- A straightforward implementation of segmentation with paging
would requires 3 memory references (STE, PTE, referenced word) so a
TLB is crucial.
- Some books carelessly say that segments are of fixed size.
This is wrong.
They are of variable size with a fixed maximum and possible with the
requirement that the size of a segment is a multiple of the page size.
- The first example of segmentation with paging was Multics.
- Keep protection and sharing information on segments.
This works well for a number of reasons.
- A segment is variable size.
- Segments and their boundaries are user (i.e., linker) visible.
- Segments are shared by sharing their page tables. This
eliminates the problem mentioned above with
shared pages.
- Do replacement on pages so there is no placement question and
no external fragmentation.
- Do fetch-on-demand with pages (i.e., do demand paging).
- In general, segmentation with demand paging works well and is
widely used. The only problems are the complexity and the resulting 3
memory references for each user memory reference. The complexity is
real, but can be managed. The three memory references would be fatal
were it not for TLBs, which considerably ameliorate the problem. TLBs
have high hit rates and for a TLB hit there is essentially no penalty.
Homework: 30.
Some last words on memory management.
- Segmentation / Paging / Demand Loading (fetch-on-demand)
- Each is a yes or no alternative.
- Gives 8 possibilities.
- Placement and Replacement.
- Internal and External Fragmentation.
- Page Size and locality of reference.
- Multiprogramming level and medium term scheduling.
================ Start Lecture #14
================
Midterm Exam
================ Start Lecture #15
================
Reviewed Answers to Midterm Exam
Allan Gottlieb