Operating Systems
2000-01 Fall
M 5:00-6:50
Ciww 109
Allan Gottlieb
gottlieb@nyu.edu
http://allan.ultra.nyu.edu/~gottlieb
715 Broadway, Room 1001
212-998-3344
609-951-2707
email is best
================ Start Lecture #13
================
RAID (Redundant Array of Inexpensive Disks)
- Tanenbaum's treatment is not very good.
- The name RAID is from Berkeley.
- IBM changed the name to Redundant Array of Independent
Disks. I wonder why?
- A simple form is mirroring, where two disks contain the
same data.
- Another simple form is striping (interleaving) where consecutive
blocks are spread across multiple disks. This helps bandwidth, but is
not redundant. Thus it shouldn't be called RAID, but it sometimes is.
- One of the normal RAID methods is to have N (say 4) data disks and one
parity disk. Data is striped across the data disks and the bitwise
parity of these sectors is written in the corresponding sector of the
parity disk.
- On a read if the block is bad (e.g., if the entire disk is bad or
even missing), the system automatically reads the other blocks in the
stripe and the parity block in the stripe. Then the missing block is
just the bitwise exclusive or of all these blocks.
- For reads this is very good. The failure free case has no penalty
(beyond the space overhead of the parity disk). The error case
requires N+1 (say 5) reads.
- A serious concern is the small write problem. Writing a sector
requires 4 I/O. Read the old data sector, compute the change, read
the parity, compute the new parity, write the new parity and the new
data sector. Hence one sector I/O became 4, which is a 300% penalty.
- Writing a full stripe is not bad. Compute the parity of the N
(say 4) data sectors to be written and then write the data sectors and
the parity sector. Thus 4 sector I/Os become 5, which is only a 20%
penalty and is smaller for larger N, i.e., larger stripes.
- A variation is to rotate the parity. That is, for some stripes
disk 1 has the parity, for others disk 2, etc. The purpose is to not
have a single parity disk since that disk is needed for all small
writes and could become a point of contention.
5.3.3: Error Handling
Disks error rates have dropped in recent years. Moreover, bad
block forwarding is done by the controller (or disk electronic) so
this topic is no longer as important for OS.
5.3.4: Track Caching
Often the disk/controller caches a track, since the
seek penalty has already been paid. In fact modern disks have
megabyte caches that hold recently read blocks. Since modern disks
cheat and don't have the same number of blocks on each track, it is
better for the disk electronics (and not the OS or controller) to do
the caching since it is the only part of the system to know the true
geometry.
5.3.5: Ram Disks
- Fairly clear. Organize a region of memory as a set of blocks and
pretend it is a disk.
- A problem is that memory is volatile.
- Often used during OS installation, before disk drivers are
available (there are many types of disk but all memory looks
the same so only one ram disk driver is needed).
5.4: Clocks
Also called timers.
5.4.1: Clock Hardware
- Generates an interrupt when timer goes to zero
- Counter reload can be automatic or under software (OS) control.
- If done automatically, the interrupt occurs periodically and thus
is perfect for generating a clock interrupt at a fixed period.
5.4.2: Clock Software
- TOD: Bump a counter each tick (clock interupt). If counter is
only 32 bits must worry about overflow so keep two counters: low order
and high order.
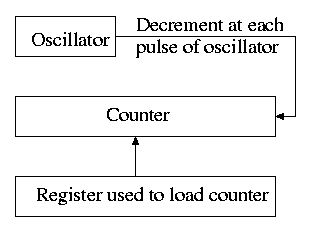
- Time quantum for RR: Decrement a counter at each tick. The quantum
expires when counter is zero. Load this counter when the scheduler
runs a process.
- Accounting: At each tick, bump a counter in the process table
entry for the currently running process.
- Alarm system call and system alarms:
- Users can request an alarm at some future time and the system
also needs to do things specific future times (e.g. turn off
floppy motor).
- The conceptually simplest solution is to have one timer for
each event. Instead, we simulate many timers with just one.
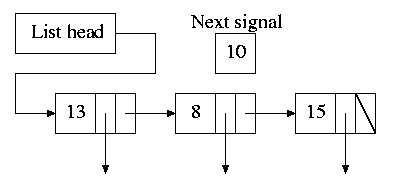
- The data structure on the right works well.
- The time in each list entry is the time after the
preceding entry that this entry's alarm is to ring. For example,
if the time is zero, this event occurs at the same time as the
previous event. The other
entry is a pointer to the action to perform.
- At each tick, decrement next-signal.
- When next-signal goes to zero,
process the first entry on the list and any others following
immediately after with a time of zero (which means they are to be
simultaneous with this alarm). Then set next-signal to the value
in the next alarm.
- Profiling
- Want a histogram giving how much time was spent in each 1KB
(say) block of code.
- At each tick check the PC and bump the appropriate counter.
- At the end of the run can assign the 1K blocks to software
modules.
- If use fine granularity (say 10B instead of 1KB) get higher
accuracy but more memory overhead.
Homework: 12
5.5: Terminals
5.5.1: Terminal Hardware
Quite dated. It is true that modern systems can communicate to a
hardwired ascii terminal, but most don't. Serial ports are used, but
they are normally connected to modems and then some protocol (SLIP,
PPP) is used not just a stream of ascii characters.
5.5.2: Memory-Mapped Terminals
- Less dated. But it still discusses the character not graphics
interface.
- Today, the idea is to have the software write into video memory
the bits to be put on the screen and then the graphics controller
converts these bits to analog signals for the monitor (actually laptop
displays and very modern monitors are digital).
- But it is much more complicated than this. The graphics
controllers can do a great deal of video themselves (like filling).
- This is a subject that would take many lectures to do well.
Keyboards
Tanenbaum description of keyboards is correct.
- At each key press and key release a code is written into the
keyboard controller and the computer is interrupted.
- By remembering which keys have been depressed and not released
the software can determine Cntl-A, Shift-B, etc.
5.5.3: Input Software
- We are just looking at keyboard input. Once again graphics is too
involved to be treated here.
- There are two fundamental modes of input, sometimes called
raw and cooked.
- In raw mode the application sees every ``character'' the user
types. Indeed, raw mode is character oriented.
- All the OS does is convert the keyboard ``scan codes'' to
``characters'' and and pass these characters to the application.
- Some examples
- down-cntl down-x up-x up-cntl is converted to cntl-x
- down-cntl up-cntl down-x up-x is converted to x
- down-cntl down-x up-cntl up-x is converted to cntl-x (I just
tried it to be sure).
- down-x down-cntl up-x up-cntl is converted to x
- Full screen editors use this mode.
- Cooked mode is line oriented. The OS delivers lines to the
application program.
- Special characters are interpreted as editing characters
(erase-previous-character, erase-previous-word, kill-line, etc).
- Erased characters are not seen by the application but are
erased by the keyboard driver.
- Need an escape character so that the editing characters can be
passed to the application if desired.
- The cooked characters must be echoed (what should one do if the
application is also generating output at this time?)
- The (possibly cooked) characters must be buffered until the
application issues a read (and an end-of-line EOL has been received
for cooked mode).
5.5.4: Output Software
Again too dated and the truth is too complicated to deal with in a
few minutes.
Homework: 16.
Chapter 6: Deadlocks
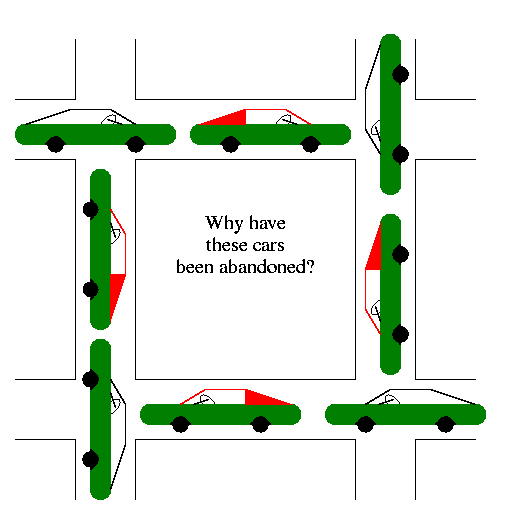
A deadlock occurs when a every member of a set of
processes is waiting for an event that can only be caused
by a member of the set.
Often the event waited for is the release of a resource.
In the automotive world deadlocks are called gridlocks.
- The processes are the cars.
- The resources are the spaces occupied by the cars
Reward: One point extra credit on the final exam
for anyone who brings a real (e.g., newspaper) picture of an
automotive deadlock. You must bring the clipping to the final and it
must be in good condition. Hand it in with your exam paper.
For a computer science example consider two processes A and B that
each want to print a file currently on tape.
- A has obtained ownership of the printer and will release it after
printing one file.
- B has obtained ownership of the tape drive and will release it after
reading one file.
- A tries to get ownership of the tape drive, but is told to wait
for B to release it.
- B tries to get ownership of the printer, but is told to wait for
A to release the printer.
Bingo: deadlock!
6.1: Resources:
The resource is the object granted to a process.
- Resources come in two types
- Preemptable, meaning that the resource can be
taken away from its current owner (and given back later). An
example is memory.
- Non-preemptable, meaning that the resource
cannot be taken away. An example is a printer.
- The interesting issues arise with non-preemptable resources so
those are the ones we study.
- Life history of a resource is a sequence of
- Request
- Allocate
- Use
- Release
- Processes make requests, use the resourse, and release the
resourse. The allocate decisions are made by the system and we will
study policies used to make these decisions.
6.2: Deadlocks
To repeat: A deadlock occurs when a every member of a set of
processes is waiting for an event that can only be caused
by a member of the set.
Often the event waited for is the release of
a resource.
6.3: Necessary conditions for deadlock
The following four conditions (Coffman; Havender) are
necessary but not sufficient for deadlock. Repeat:
They are not sufficient.
- Mutual exclusion: A resource can be assigned to at most one
process at a time (no sharing).
- Hold and wait: A processing holding a resource is permitted to
request another.
- No preemption: A process must release its resources; they cannot
be taken away.
- Circular wait: There must be a chain of processes such that each
member of the chain is waiting for a resource held by the next member
of the chain.
6.2.2: Deadlock Modeling
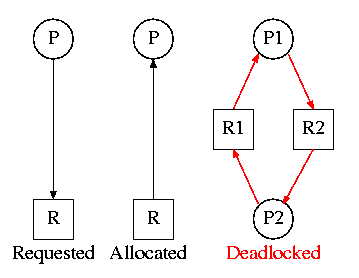
On the right is the Resource Allocation Graph,
also called the Reusable Resource Graph.
- The processes are circles.
- The resources are squares.
- An arc (directed line) from a process P to a resource R signifies
that process P has requested (but not yet been allocated) resource R.
- An arc from a resource R to a process P indicates that process P
has been allocated resource R.
Homework: 1.
Consider two concurrent processes P1 and P2 whose programs are.
P1: request R1 P2: request R2
request R2 request R1
release R2 release R1
release R1 release R2
On the board draw the resource allocation graph for various possible
executions of the processes, indicating when deadlock occurs and when
deadlock is no longer avoidable.
There are four strategies used for dealing with deadlocks.
- Ignore the problem
- Detect deadlocks and recover from them
- Avoid deadlocks by carefully deciding when to allocate resources.
- Prevent deadlocks by violating one of the 4 necessary conditions.
6.3: Ignoring the problem--The Ostrich Algorithm
The ``put your head in the sand approach''.
- If the likelihood of a deadlock is sufficiently small and the cost
of avoiding a deadlock is sufficiently high it might be better to
ignore the problem. For example if each PC deadlocks once per 100
years, the one reboot may be less painful that the restrictions needed
to prevent it.
- Clearly not a good philosophy for nuclear missile launchers.
- For embedded systems (e.g., missile launchers) the programs run
are fixed in advance so many of the questions Tanenbaum raises (such
as many processes wanting to fork at the same time) don't occur.
6.4: Detecting Deadlocks and Recovering from them
6.4.1: Detecting Deadlocks with single unit resources
Consider the case in which there is only one
instance of each resource.
- So a request can be satisfied by only one specific resource.
- In this case the 4 necessary conditions for deadlock are also
sufficient.
- Remember we are making an assumption (single unit resources) that
is often invalid. For example, many systems have several printers and
a request is given for ``a printer'' not a specific printer.
Similarly, one can have many tape drives.
- So the problem comes down to finding a directed cycle in the resource
allocation graph. Why?
Answer: Because the other three conditions are either satisfied by the
system we are studying or are not in which case deadlock is not a
question. That is, conditions 1,2,3 are conditions on the system in
general not on what is happening right now.
To find a directed cycle in a directed graph is not hard. The
algorithm is in the book. The idea is simple.
- For each node in the graph do a depth first traversal (hoping the
graph is a DAG (directed acyclic graph), building a list as you go
down the DAG.
- If you ever find the same node twice on your list, you have found
a directed cycle and the graph is not a DAG and deadlock exists among
the processes in your current list.
- If you never find the same node twice, the graph is a DAG and no
deadlock occurs.
- The searches are finite since the list size is bounded by the
number of nodes.
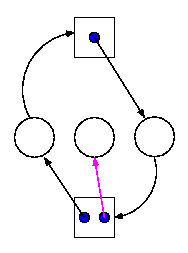
6.4.2: Detecting Deadlocks with multiple unit resources
This is more difficult.
- The figure on the right shows a resource allocation graph with
multiple unit resources.
- Each unit is represented by a dot in the box.
- Request edges are drawn to the box since they represent a request
for any dot in the box.
- Allocation edges are drawn from the dot to represent that this
unit of the resource has been assigned (but all units of a resource
are equivalent and the choice of which one to assign is arbitrary).
- Note that there is a directed cycle in black, but there is no
deadlock. Indeed the middle process might finish, erasing the magenta
arc and permitting the blue dot to satisfy the rightmost process.
- The book gives an algorithm for detecting deadlocks in this more
general setting. The idea is as follows.
- look fora process that might be able to terminate (i.e., all
its request arcs can be satisfied).
- If one is found pretend that it does terminate (erase all its
arcs), and repeat step 1.
- If any processes remain, they are deadlocked.
- We will soon do in detail an algorithm (the Banker's algorithm) that
has some of this flavor.
6.4.3: Recovery from deadlock
Preemption
Perhaps you can temporarily preempt a resource from a process. Not
likely.
Rollback
Database (and other) systems take periodic checkpoints. If the
system does take checkpoints, one can roll back to a checkpoint
whenever a deadlock is detected. Somehow must guarantee forward
progress.
Kill processes
Can always be done but might be painful. For example some
processes have had effects that can't be simply undone. Print, launch
a missile, etc.