Operating Systems
2000-01 Fall
M 5:00-6:50
Ciww 109
================ Start Lecture #7
================
3.4.4: Second chance PRA
Similar to the FIFO PRA but when time choosing a victim, if the page
at the head of the queue has been referenced (R bit set), don't evict
it.
Instead reset R and move the page to the rear of the queue (so it
looks new).
The page is being a second chance.
What if all frames have been referenced?
Becomes the same as fifo (but takes longer).
Might want to turn off the R bit more often (say every k clock ticks).
3.4.5: Clock PRA
Same algorithm as 2nd chance, but a better (and I would say obvious)
implementation: Use a circular list.
Do an example.
LIFO PRA
This is terrible! Why?
Ans: All but the last frame are frozen once loaded so you can replace
only one frame. This is especially bad after a phase shift in the
program when it is using all new pages.
3.4.6:Least Recently Used (LRU) PRA
When a page fault occurs, choose as victim that page that has been
unused for the longest time, i.e. that has been least recently used.
LRU is definitely
- Implementable: The past is knowable.
- Good: Simulation studies have shown this.
- Difficult. Essentially need to either:
- Keep a time stamp in each PTE, updated on each reference
and scan all the PTEs when choosing a victim to find the PTE
with the oldest timestamp.
- Keep the PTEs in a linked list in usage order, which means
on each reference moving the PTE to the end of the list
Homework: 19, 20
A hardware cutsie in Tanenbaum
- For n pages, keep an nxn bit matrix.
- On a reference to page i, set row i to all 1s and col i to all 0s
-
At any time the 1 bits in the rows are ordered by inclusion. I.e. one
row's 1s are a subset of another row's 1s, which is a subset of a
third. (Tanenbaum forgets to mention this.)
-
So the row with the fewest 1s is a subset of all the others and is
hence least recently used
- Cute, but still impractical.
3.4.7: Approximating LRU in Software
The Not Frequently Used (NFU) PRA
- Include a counter in each PTE (and have R in each PTE).
- Set counter to zero when page is brought into memory.
- For each PTE, every k clock ticks.
- Add R to counter.
- Clear R.
- Choose as victim the PTE with lowest count.
The Aging PRA
NFU doesn't distinguish between old references and recent one. The
following modification does distinguish.
- Include a counter in each PTE (and have R in each PTE).
- Set counter to zero when page is brought into memory.
- For each PTE, every k clock ticks.
- Shift counter right one bit.
- Insert R as new high order bit (HOB).
- Clear R.
- Choose as victim the PTE with lowest count.
| R | counter |
|---|
| 1 | 10000000 |
|
| 0 | 01000000 |
|
| 1 | 10100000 |
|
| 1 | 11010000 |
|
| 0 | 01101000 |
|
| 0 | 00110100 |
|
| 1 | 10011010 |
|
| 1 | 11001101 |
|
| 0 | 01100110 |
|
Homework: 21, 25
3.5: Modeling Paging Algorithms
3.5.1: Belady's anomaly
Consider a system that has no pages loaded and that uses the FIFO
PRU.
Consider the following ``reference string'' (sequences of pages referenced).
0 1 2 3 0 1 4 0 1 2 3 4
If we have 3 frames this generates 9 page faults (do it).
If we have 4 frames this generates 10 page faults (do it).
Theory has been developed and certain PRA (so called ``stack
algorithms'') cannot suffer this anomaly for any reference string.
FIFO is clearly not a stack algorithm. LRU is.
Repeat the above calculations for LRU.
3.6: Design issues for (demand) Paging
3.6.1 & 3.6.2: The Working Set Model and Local vs Global Policies
I will do these in the reverse order (which makes more sense). Also
Tanenbaum doesn't actually define the working set model, but I shall.
A local PRA is one is which a victim page is chosen
among the pages of the same process that requires a new page. That is
the number of pages for each process is fixed. So LRU means the page
least recently used by this process.
- Of course we can't have a purely local policy, why?
Answer: A new process has no pages and even if we didn't apply this for
the first page loaded, the process would remain with only one page.
- Perhaps wait until a process has been running a while.
- A global policy is one in which the choice of
victim is made among all pages of all processes.
If we apply global LRU indiscriminately with some sort of RR processor
scheduling policy, and memory is somewhat over-committed, then by the
time we get around to a process, all the others have run and have
probably paged out this process.
If this happens each process will need to page fault at a high
rate; this is called thrashing.
It is therefore important to get a good
idea of how many pages a process needs, so that we can balance the
local and global desires.
The working set policy (Peter Denning)
The goal is to specify which pages a given process needs to have
memory resident in order for the give process to run without too many
page faults.
- But this is impossible since it requires predicting the future.
- So we make the assumption that the immediate future is well
approximated by the immediate past.
-
Measure time in units of memory references, so t=1045 means the time
when the 1045th memory reference is issued.
- In fact we measure time separately
for each process, so t=1045 really means the time when this process
made its 1045th memory reference.
-
W(t,&omega) is the set of pages referenced (by the given process) from
time t-ω to time t.
- That is, W(t,ω) is the set pages referenced during
the window of size ω ending at time t.
- That is, W(t,ω) is the set of pages referenced by the last
ω memory references ending at reference t.
- W(t,ω) is called the working set at time t
(with window ω).
- Netscape doesn't (yet) support ω to give the Greek letter.
Ouch
-
w(t,ω) is the size of the set W(t,ω), i.e. is the
number of pages referenced in the window.
The idea of the working set policy is to ensure that each process
keeps its working set in memory.
- One possibility is to allocate w(t,ω) frames to each process
(this number differs for each process and changes with time) and then
use a local policy.
- What if there aren't enough frames to do this?
- Ans: Reduce the multiprogramming level (MPL)! That is, we have a
connection between memory management and process management. This is
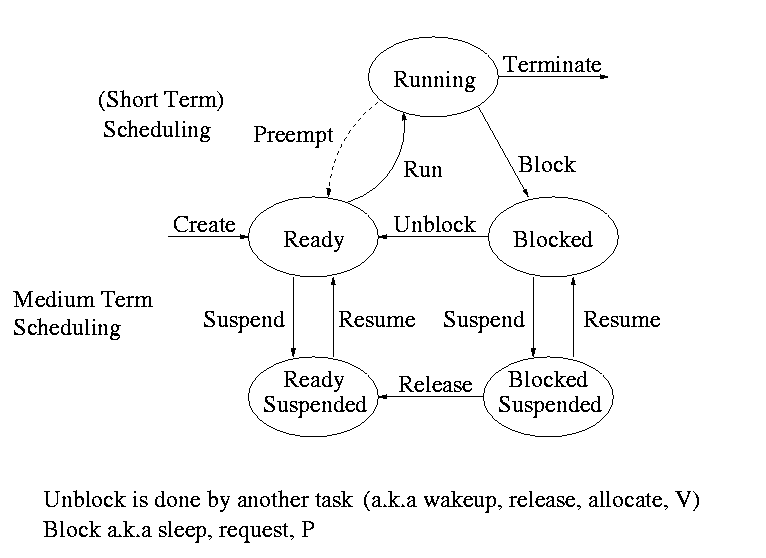
the suspend/resume arcs we saw way back when.
Interesting questions include:
- What value should be used for ω?
Experiments have been done and ω is surprisingly robust (i.e.,
for a given system a fixed value works reasonably for a wide variety
of job mixes)
- How should we calculate W(t,ω)?
Hard so do exactly so ...
... various approximations to the working set, have been devised.
- Wsclock
- Use the aging algorithm above to maintain a counter for
each PTE and declare a page whose counter is above a certain threshold
to be part of the working set.
- Apply the clock algorithm globally (i.e. to all pages) but
refuse to page out any page in a working set, the resulting algorithm
is called wsclock.
- What if we find there are no pages we can page out?
Answer: Reduce the MPL.
- Page Fault Frequency (PFF)
- For each process keep track of the page fault frequency, which
is the number of faults divided by the number of references.
- Actually, must use a window or a weighted calculation since
you are really interested in the recent page fault frequency.
- If the PFF is too high, allocate more frames to this process.
Either
- Raise its number of frames and use local policy; or
- Bar its frames from eviction (for a while) and use a
global policy.
- What if there are not enough frames?
Answer: Reduce the MPL.
3.6.3: Page size
- Page size ``must'' be a multiple of the disk block size. Why?
Answer: When copying out a page if you have a partial disk block, you
must do a read/modify/write (i.e., 2 I/Os).
- Important property of I/O that we will learn later this term is
that eight I/Os each 1KB takes considerably longer than one 8KB I/O
- Characteristics of a large page size.
- Good for user I/O.
- If I/O done using physical addresses, then I/O crossing a
page boundary is not contiguous and hence requires multiple
I/Os
- If I/O uses virtual addresses, then page size doesn't effect
this aspect of I/O. That is the addresses are contiguous in virtual
address and hence one I/O is done.
- Good for demand paging I/O.
- Better to swap in/out one big page than several small
pages.
- But if page is too big you will be swapping in data that is
really not local and hence might well not be used.
- Large internal fragmentation (1/2 page size).
- Small page table.
- A very larg page size leads to very few pages. Process will
have many faults if using demand
paging and the process frequently references more regions than
frames.
- A mall page size has the opposite characteristics.
3.6.4: Implementation Issues
Don't worry about instruction backup. Very machine dependent and
modern implementations tend to get it right.
Locking (pinning) pages
We discussed pinning jobs already. The
same (mostly I/O) considerations apply to pages.
Shared pages
Really should share segments.
- Must keep reference counts or something so that when a process
terminates, pages (even dirty pages) it shares with another process
are not automatically discarded.
- Similarly, a reference count would make a widely shared page (correctly)
look like a poor choice for a victim.
- A good place to store the reference count would be in a structure
pointed to by both PTEs. If stored in the PTEs, must keep them
consistent between processes.
Allan Gottlieb
gottlieb@nyu.edu
http://allan.ultra.nyu.edu/~gottlieb
715 Broadway, Room 1001
212-998-3344
609-951-2707
email is best