- We know where it will be if it is there at all (memory block number mod number of blocks in the cache).
- But many memory blocks are assigned to that same cache block. For example, in the diagram above all the green blocks in memory are assigned to the one green block in the cache.
- So we need the ``rest'' of the address (i.e., the part lost when we reduced the block number modulo the size of the cache) to see if the block in the cache is the memory block of interest.
- The cache stores the rest of the address, called the tag and we check the tag when looking for a block
-
Also stored is a valid bit per cache block so that we
can tell if there is a memory block stored in this cache
block.
For example, when the system is powered on, all the cache blocks are invalid.
Example on pp. 547-8.
- Tiny 8 word direct mapped cache with block size one word and all references are for a word.
- In the table to follow all the addresses are word addresses. For example the reference to 3 means the reference to word 3 (which includes bytes 12, 13, 14, and 15).
- If reference experience a miss and the cache block is valid, the current reference is discarded (in this example only) and the new reference takes its place.
- Do this example on the board showing the address store in the cache at all times
| Address(10) | Address(2) | hit/miss | block# |
|---|---|---|---|
| 22 | 10110 | miss | 110 |
| 26 | 11010 | miss | 010 |
| 22 | 10110 | hit | 110 |
| 26 | 11010 | hit | 010 |
| 16 | 10000 | mis | 000 |
| 3 | 00011 | miss | 011 |
| 16 | 10000 | hit | 000 |
| 18 | 10010 | miss | 010 |
The basic circuitry for this simple cache to determine hit or miss and to return the data is quite easy. We are showing a 1024 word (= 4KB) direct mapped cache with block size = reference size = 1 word.
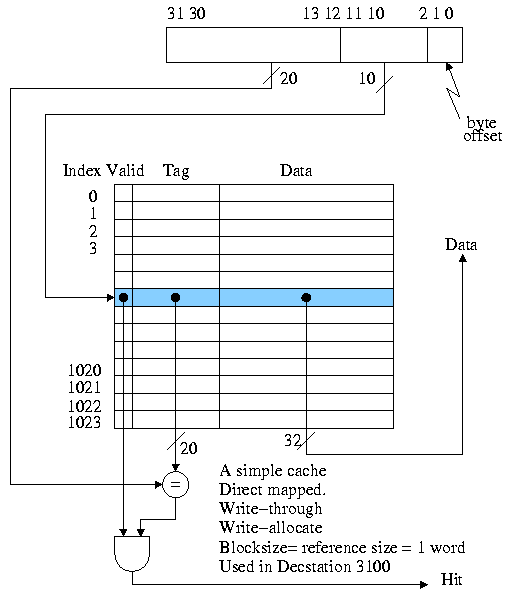
Calculate on the board the total number of bits in this cache.
Homework: 7.1 7.2 7.3
Processing a read for this simple cache.
- The action required for a hit is obvious, namely return the data found to the processor.
-
For a miss, the action best action is clear, but not completely
obvious.
- Clearly we must go to central memory to fetch the requested data since it is not available in the cache.
- The only question is should we place this new data in the cache replacing the old, or should we maintain the old.
- But it is clear that we want to store the new data instead of the old.
- Why?
Ans: Temporal Locality - What do we do with the old data, can we just toss it or do we
need to write it back to central memory.
Ans: It depends! We will see shortly that the action needed on a read miss, depends on our action for write hits.
Skip the section ``handling cache misses'' as it discusses the multicycle and pipelined implementations of chapter 6, which we skipped. For our single cycle processor implementation we just need to note a few points.
- The instruction and data memory are replaced with caches.
- On cache misses one needs to fetch/store the desired datum or instruction from/to central memory.
- This is very slow and hence our cycle time must be very long.
- A major reason why the single cycle implementation is not used in practice.
Processing a write for our simple cache (direct mapped with block size = reference size = 1 word).
-
We have 4 possibilities:
-
For a write hit we must choose between
Write through and Write back.
- Write through: Write the data to memory as well as to the cache.
- Write back: Don't write to memory now, do it later when this cache block is evicted.
- Thus the write hit policy effects our read miss policy as mentioned just above.
-
For a write miss we must choose between
write-allocate and
write-no-allocate
(also called
store-allocate and
store-no-allocate).
-
Write-allocate:
- Write the new data into the cache.
- If the cache is write through, discard the old data (since it is in memory) and write the new data to memory.
- If the cache is write back, the old data must now be written back to memory, but the new data is not written to memory.
-
Write-no-allocate:
- Leave the cache alone and just write central memory with the new data.
- Not as popular since temporal locality favors write-allocate.
-
Write-allocate:
-
For a write hit we must choose between
Write through and Write back.
-
The simplist is write-through, write-allocate.
- We are still assuming block size = reference size = 1 word and direct mapped.
-
For any write (hit or miss) do the following:
- Index the cache using the correct LOBs (i.e., not the very lowest order bits as these give the byte offset).
-
Write the data and the tag into the cache.
- For a hit, we are overwriting the tag with itself.
- For a miss, we are performing a write allocate and, since the cache is write-through, memory is guaranteed to be correct, we can simply overwrite the current entry.
- Set Valid to true.
- Send request to main memory.
-
Poor performance
- For the GCC benchmark 11% of the operations are stores.
- If we assume an infinite speed central memory (i.e., a zero miss penalty) or a zero miss rate, the CPI is 1.2 for some reasonable estimate of instruction speeds.
- If we assume a 10 cycle store penalty (conservative) since we have to write main memory (recall we are using a write-through cache), then the CPI becomes 1.2 + 10 * 11% = 2.5, which is half speed.
Improvement: Use a write buffer
- Hold a few (four is common) writes at the processor while they are being processed at memory.
- As soon as the word is written into the write buffer, the instruction is considered complete and the next instruction can begin.
- Hence the write penalty is eliminated as long as the word can be written into the write buffer.
- Must stall (i.e., incur a write penalty) if the write buffer is full. This occurs if a bunch of writes occur in a short period.
- If the rate of writes is greater than the rate at which memory can handle writes, you must stall eventually. The purpose of a write-buffer (indeed of buffers in general) is to handle short bursts.
- The Decstation 3100 (which employed the simple cache structure just described) had a 4-word write buffer.
Unified vs split I and D (instruction and data) caches
- Given a fixed total size (in bytes) for caches, is it better to have two caches, one for instructions and one for data; or is it better to have a single ``unified'' cache?
- Unified is better because it automatically performs ``load balancing''. If the current program needs more data references than instruction references, the cache will accommodate. Similarly if more instruction references are needed.
- Split is better because it can do two references at once (one instruction reference and one data reference).
-
The winner is ...
split I and D. - But unified has the better (i.e. higher) hit ratio.
- So hit ratio is not the ultimate measure of good cache performance.