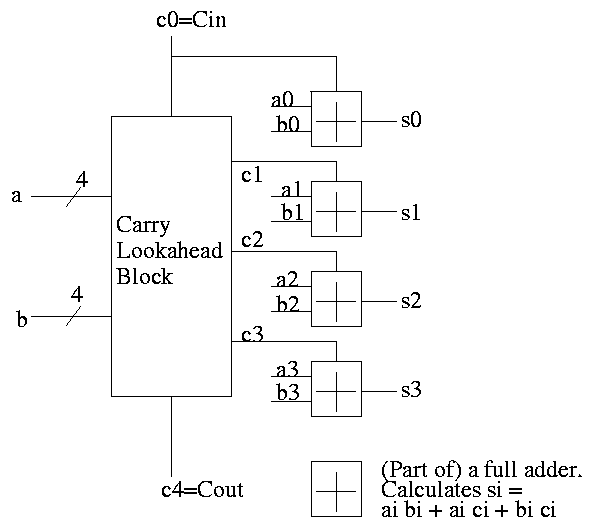
This adder is much faster than the ripple adder we did before, especially for wide (i.e., many bit) addition.
To summarize, using a subscript i to represent the bit number,
to generate a carry: gi = ai bi
to propagate a carry: pi = ai+bi
H&P give a plumbing analogue for generate and propagate.
Given the generates and propagates, we can calculate all the carries for a 4-bit addition (recall that c0=Cin is an input) as follows (this is the formula version of the plumbing):
c1 = g0 + p0 c0 c2 = g1 + p1 c1 = g1 + p1 g0 + p1 p0 c0 c3 = g2 + p2 c2 = g2 + p2 g1 + p2 p1 g0 + p2 p1 p0 c0 c4 = g3 + p3 c3 = g3 + p3 g2 + p3 p2 g1 + p3 p2 p1 g0 + p3 p2 p1 p0 c0
Thus we can calculate c1 ... c4 in just two additional gate delays (where we assume one gate can accept upto 5 inputs). Since we get gi and pi after one gate delay, the total delay for calculating all the carries is 3 (this includes c4=Carry-Out)
Each bit of the sum si can be calculated in 2 gate delays given ai, bi, and ci. Thus, for 4-bit addition, 5 gate delays after we are given a, b and Carry-In, we have calculated s and Carry-Out.
So, for 4-bit addition, the faster adder takes time 5 and the slower adder time 8.
Now we want to put four of these together to get a fast 16-bit adder.
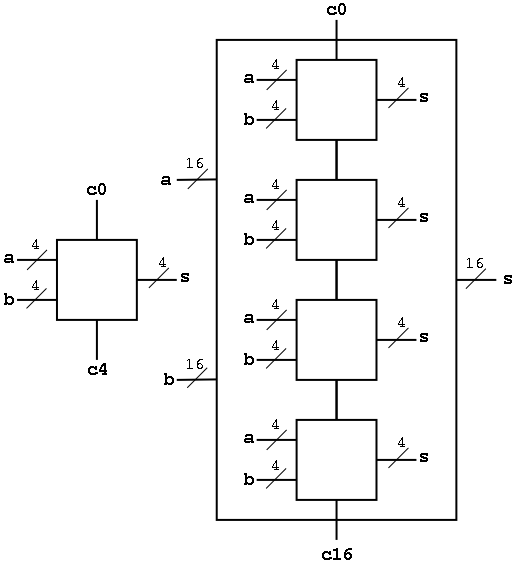
As black boxes, both ripple-carry adders and carry-lookahead adders (CLAs) look the same.
We could simply put four CLAs together and let the Carry-Out from one be the Carry-In of the next. That is, we could put these CLAs together in a ripple-carry manner to get a hybrid 16-bit adder.
We want to do better so we will put the 4-bit carry-lookahead adders together in a carry-lookahead manner. Thus the diagram above is not what we are going to do.
We start by determining ``super generate'' and ``super propagate'' bits.
P0 = p3 p2 p1 p0 Does the low order 4-bit adder
propagate a carry?
P1 = p7 p6 p5 p4
P2 = p11 p10 p9 p8
P3 = p15 p14 p13 p12 Does the high order 4-bit adder
propagate a carry?
G0 = g3 + p3 g2 + p3 p2 g1 + p3 p2 p1 g0 Does low order 4-bit
adder generate a carry
G1 = g7 + p7 g6 + p7 p6 g5 + p7 p6 p5 g4
G2 = g11 + p11 g10 + p11 p10 g9 + p11 p10 p9 g8
G3 = g15 + p15 g14 + p15 p14 g13 + p15 p14 p13 g12
From these super generates and super propagates, we can calculate the
super carries, i.e. the carries for the four 4-bit adders.
C1 = G0 + P0 c0 C2 = G1 + P1 C1 = G1 + P1 G0 + P1 P0 c0 C3 = G2 + P2 C2 = G2 + P2 G1 + P2 P1 G0 + P2 P1 P0 c0 C4 = G3 + P3 C3 = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 G0 + P3 P2 P1 P0 c0
Now these C's (together with the original inputs a and b) are just what the 4-bit CLAs need.
How long does this take, again assuming 5 input gates?
In summary, a 16-bit CLA takes 9 cycles instead of 32 for a ripple carry adder and 14 for the mixed adder.
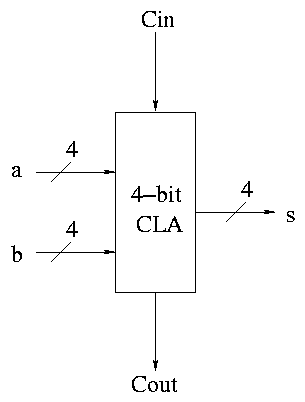
Some pictures follow.
Take our original picture of the 4-bit CLA and collapse
the details so it looks like.
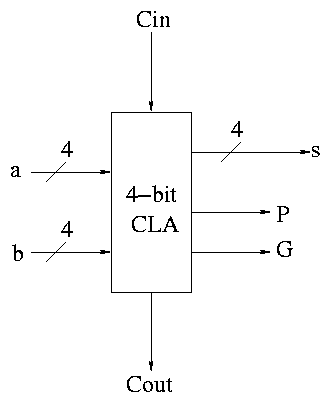
Next include the logic to calculate P and G.
Now put four of these with a CLA block (to calculate C's from P's, G's and Cin) and we get a 16-bit CLA. Note that we do not use the Cout from the 4-bit CLAs.
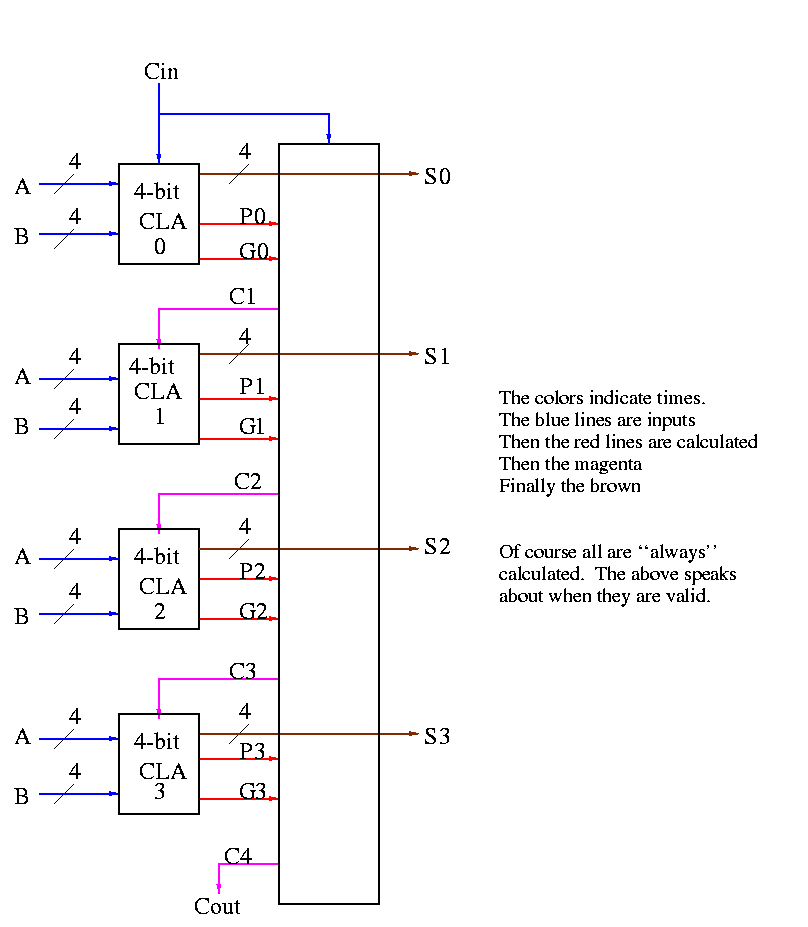
Note that the tall skinny box is general. It takes 4 Ps 4Gs and Cin and calculates 4Cs. The Ps can be propagates, superpropagates, superduperpropagates, etc. That is, you take 4 of these 16-bit CLAs and the same tall skinny box and you get a 64-bit CLA.
Homework: 4.44, 4.45
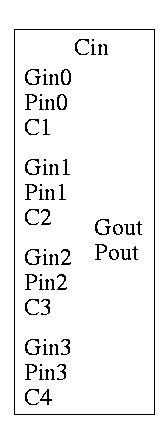
As noted just above the tall skinny box is useful for all size CLAs. To expand on that point and to review CLAs, let's redo CLAs with the general box.
Since we are doing 4-bits at a time, the box takes 9=2*4+1 input bits and produces 6=4+2 outputs
C1 = G0 + PO Cin C2 = G1 + P1 G0 + P1 P0 Cin C3 = G2 + P2 G1 + P2 P1 G0 + P2 P1 P0 Cin C4 = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 G0 + P3 P2 P1 P0 Cin Gout = G3 + P3 G2 + P3 P2 G1 + P3 P2 P1 Go Pout = P3 P2 P1 P0
A 4-bit adder is now
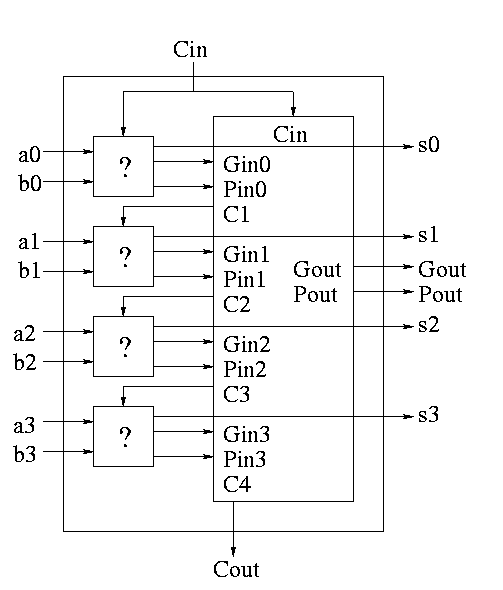
What does the ``?'' box do?
Now take four of these 4-bit adders and use the identical CLA box to get a 16-bit adder
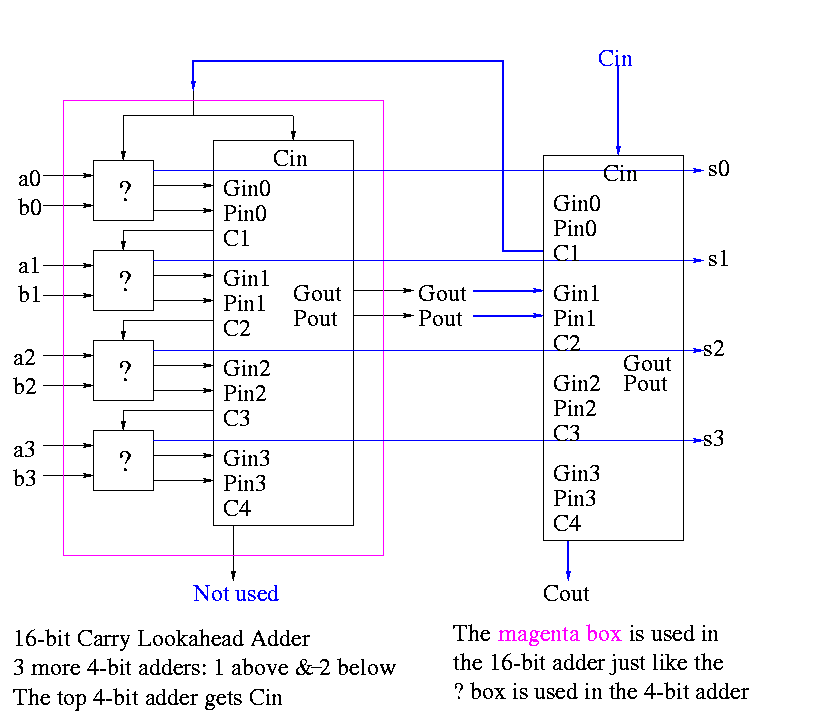
Four of these 16-bit adders with the identical CLA box to gives a 64-bit adder.