================ Start Lecture #4
================
3.1.1: The Process Model
Even though in actuality there are many processes running at once, the
OS gives each process the illusion that it is running alone.
- Virtual time: The time used by just this
processes. Virtual time progresses at
a rate independent of other processes. Actually, this is false, the
virtual time is
typically incremented a little during systems calls used for process
switching; so if there are more other processors more ``overhead''
virtual time occurs.
- Virtual memory: The memory as viewed by the
process. Each process typically believes it has a contiguous chunk of
memory starting at location zero. Of course this can't be true of all
processes (or they would be using the same memory) and in modern
systems it is actually true of no processes (the memory assigned is
not contiguous and does not include location zero).
Virtual time and virtual memory are examples of abstractions
provided by the operating system to the user processes so that the
latter ``sees'' a more pleasant virtual machine than actually exists.
Process Hierarchies
Modern general purpose operating systems permit a user to create and
destroy processes. In unix this is done by the fork
system call, which creates a child process, and the
exit system call, which terminates the current
process. After a fork both parent and child keep running (indeed they
have the same program text) and each can fork off other
processes. A process tree results. The root of the tree is a special
process created by the OS during startup.
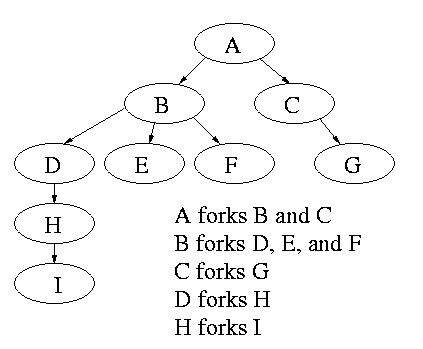
MS-DOS is not multiprogrammed so when one process starts another,
the first process is blocked and waits until the second is finished.
Process states and transitions
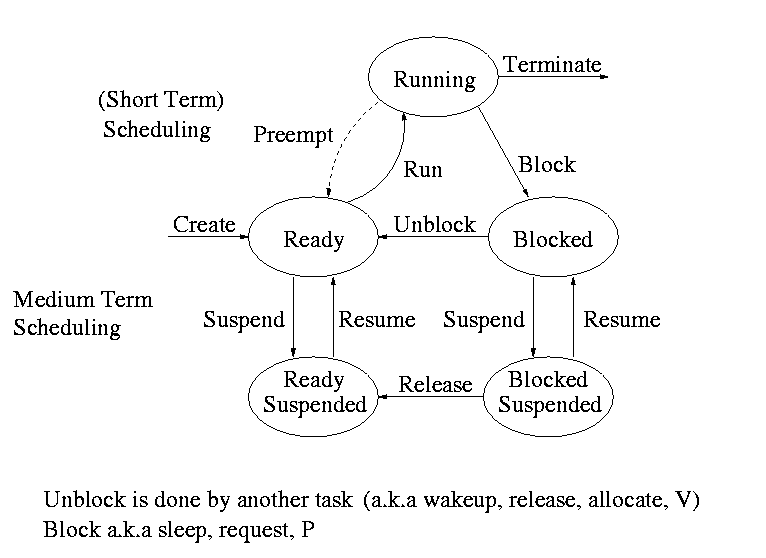
The above diagram contains a great deal of information.
- Consider a running process P that issues an I/O request
- The process blocks
- At some later point, a disk interrupt occurs and the driver
detects that P's request is satisfied.
- P is unblocked, i.e. is moved from blocked to ready
- At some later time the processor looks for a ready job to run
and picks P
- A preemptive scheduler has the dotted line preempt;
A non-preemptive scheduler doesn't
- The number of processes changes only for two arcs: create and
terminate
- Suspend and resume are medium term scheduling
- Done on a larger time scale
- Involves memory management as well
- Sometimes called two level scheduling
One can organize an OS around the scheduler.
- Write a minimal ``kernel'' consisting of the scheduler, interrupt
handlers, and IPC (interprocess communication)
- The rest of the OS consists of kernel processes (e.g. memory,
filesystem) that act as servers for the user processes (which of
course act as clients.
- The system processes also act as clients (of other system processes).
- Called a client server organization
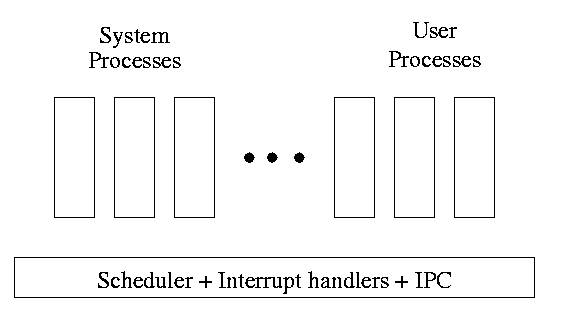
The above is called the client-server model and is one Tanenbaum likes.
His ``Minix'' operating system works this way.
Indeed, there was reason to believe that it would dominate. But that
hasn't happened. Such an OS is sometimes called server
based. Systems like traditional unix or linux would then be
called self-service since the user process serves itself.
That is, the user process switches
to kernel mode and performs the system call. To repeat: the same
process changes back and forth from/to user<-->system mode and
services itself.
2.1.3: Implementation of Processes
The OS organizes the data about each process in a table naturally
called the process table. Each entry in this table
is called a process table entry or PTE.
- One entry per process
- The central data structure for process management
- A process state transition (e.g., moving from blocked to ready) is
reflected by a change in the value of one or more
fields in the PTE
- We have converted an active entity (process) into a data structure
(PTE). Finkel calls this the level principle ``an active
entity becomes a data structure when looked at from a lower level''.
- The PTE contains a great deal of information about the process.
For example,
- Saved value of registers when process not running
- Stack pointer
- CPU time used
- Process id (PID)
- Process id of parent (PPID)
- User id (uid and euid)
- Group id (gid and egid)
- Pointer to text segment (memory for the program text)
- Pointer to data segment
- Pointer to stack segment
- UMASK (default permissions for new files)
- Current working directory
- Many others
An aside on Interrupts
In a well defined location in memory (specified by the hardware) the
OS store an interrupt vector, which contains the
address of the (first level) interrupt handler.
- Tanenbaum calls the interrupt handler the interrupt service routine.
- Actually one can have different priorities of interrupts and the
interrupt vector contains one pointer for each level. This is why it is
called a vector.
Assume a process P is running and a disk interrupt occurs for the
completion of a disk read previously issued by process Q, which is
currently blocked. Note that interrupts are unlikely to be for the
currently running process.
- The hardware stacks the program counter etc (possibly some
registers)
- Hardware loads new program counter from the interrupt vector.
- Loading the program counter causes a jump
- Steps 1 and 2 are similar to a procedure call. But the
interrupt is asynchronous
- Assembly language routine saves registers
- Assembly routine sets up new stack
- These last two steps can be called setting up the C environment
- Assembly routine calls C procedure (tanenbaum forgot this one)
- C procedure does the real work
- Determines what caused the interrupt (in this case a disk
completed an I/O)
- How does it figure out the cause?
- Which priority interrupt was activated.
- The controller can write data in memory before the
interrupt
- The OS can read registers in the controller
- Mark process Q as ready to run.
- That is move Q to the ready list (note that again
we are viewing Q as a data structure).
- The state of Q is now ready (it was blocked before).
- The code that Q needs to run initially is likely to be OS
code. For example, Q probably needs to copy the data just
read from a kernel buffer into user space.
- Now we have at least two processes ready to run: P and Q
- The scheduler decides which process to run (P or Q or
something else). Lets assume that the decision is to run P.
- The C procedure (that did the real work in the interrupt
processing) continues and returns to the assembly code.
- Assembly language restores P's state (e.g., registers) and starts
P at the point it was when the interrupt occurred.
2.2: Interprocess Communication (IPC) and Process Coordination and
Synchronization
2.2.1: Race Conditions
A race condition occurs when two processes can
interact and the outcome depends on the order in which the processes
execute.
- Imagine two processes both accessing x, which is initially 10.
- One process is to execute x <-- x+1
- The other is to execute x <-- x-1
- When both are finished x should be 10
- But we might get 9 and might get 11!
- Show how this can happen (x <-- x+1 is not atomic)
- Tanenbaum shows how this can lead to disaster for a printer
spooler
Homework: 2
2.2.2: Critical sections
We must prevent interleaving sections of code that need to be atomic with
respect to each other. That is, the conflicting sections need
mutual exclusion. If process A is executing its
critical section, it excludes process B from executing its critical
section. Conversely if process B is executing is critical section, it
excludes process A from executing its critical section.
Goals for a critical section implementation.
- No two processes may be simultaneously inside their critical
section
- No assumption may be made about the speeds or the number of CPUs
- No process outside its critical section may block other processes
- No process should have to wait forever to enter its critical
section
- I do NOT make this last requirement.
- I just require that the system as a whole make progress (so not
all processes are blocked)
- I refer to solutions that do not satisfy tanenbaum's last
condition as unfair, but nonetheless correct, solutions
- Stronger fairness conditions can also be defined
2.2.3 Mutual exclusion with busy waiting
The operating system can choose not to preempt itself. That is, no
preemption for system processes (if the OS is client server) or for
processes running in system mode (if the OS is self service).
Forbidding preemption for system processes would prevent the problem
above where x<--x+1 not being atomic crashed the printer spooler if
the spooler is part of the OS.
But this is not adequate
- Does not work for user programs. So the Unix printer spooler would
not be helped.
- Does not prevent conflicts between the main line OS and interrupt
handlers
- This conflict could be prevented by blocking interrupts while the mail
line is in its critical section.
- Indeed, blocking interrupts is often done for exactly this reason.
- Do not want to block interrupts for too long or the system
will seem unresponsive
- Does not work if the system has several processors
- Both main lines can conflict
- One processor cannot block interrupts on the other
Software solutions for two processes
Initially P1wants=P2wants=false
Code for P1 Code for P2
Loop forever { Loop forever {
P1wants <-- true ENTRY P2wants <-- true
while (P2wants) {} ENTRY while (P1wants) {}
critical-section critical-section
P1wants <-- false EXIT P2wants <-- false
non-critical-section } non-critical-section }
Explain why this works.
But it is wrong! Why?