==== Start Lecture #5 ====
See announcements on course home page
Introduces the ``Placement Question'', which hole (partition) to choose
- Best fit, worst fit, first fit, circular first fit, quick fit, Buddy
- Best fit doesn't waste big holes, but does leave slivers and
is most expensive to run.
- Worst fit avoids slivers, but eliminates all big holes so a
big job will require compaction.
- Quick fit keeps lists of some common sizes (but has other
problems, see tanenbaum)
- Buddy system
- Round request to next highest power of two (causes
internal fragmentation)
- Look in list of blocks this size (cf. quick fit)
- If list empty, go higher and split into buddies
- When returning coalesce with buddy
- Do splitting and coalescing recursively, i.e. keep
coalescing until can't and keep splitting until successful
- See tanenbaum for more details (or an algorithms book).
- A current favorite is circular first fit (aka next fit)
- Use the first hole that is big enough (first fit) but start
looking where you left off last time.
- Doesn't waste time constantly trying to use small holes that
have failed before, but does tend to use many of the big holes,
which can be a problem.
- Buddy comes with its own implementation. How about the others?
- Bit map
- Only question is how much memory does one bit represent.
- Big: Serious internal fragmentation
- Small: Many bits to store and process
- Linked list
- Each item on list says whether Hole or Process, length,
starting location
- The items on the list are not taken from the memory to be
used by processes
- Keep in order of starting addr
- Double linked
- Boundary tag
- Knuth
- Use the same memory for list items as for processes
- Don't need an entry in linked list for blocks in use, just
the avail blocks are linked
- For the in use blocks, just need a hole/process bit at
each end and the length. Keep this in the block itself.
- See knuth, the art of computer programming vol 1
Homework: 2, 4, 5. (Note to me: Remove 4 from
notes since added to previous lecture)
Also introduces the ``Replacement Question'', which victim to swap out
We will study this question more when we discuss demand paging
Considerations in choosing a victim
- Cannot replace a job that is pinned,
i.e. whose memory is tied down. For example, if Direct Memory
Access (DMA) I/O is scheduled for this process, the job is pinned
until the DMA is complete.
- Victim selection is a medium term scheduling decision
- Job that has been in a wait state for a long time is a good candidate.
- Often choose as a victim a job that has been in memory for a long
time.
- Another point is how long should it stay swapped out.
- For demand paging, where swaping out a page is not as drastic as
swapping out a job, victim is an important memory management decision
and we shall study several policies
NOTEs:
- So far the schemes have had two properties
- Each job is stored contiguously in memory. That is, the job is
contiguous in physical addresses.
- Each job cannot use more memory than exists in the system. That
is, the virtual addresses space cannot exceed the physical address
space.
- Tanenbaum now attacks the second item. I wish to do both and start
with the first
- Tanenbaum (and most of the world) uses the term ``paging'' to mean
what I call demand paging. This is unfortunate as it mixes together
two concepts
- Paging (dicing the address space) to solve the placement
problem and essentially eliminate external fragmentation.
- On demand fetching, to permit the total memory requirements of
all loaded jobs to exceed the size of physical memory.
- Tanenbaum (and most of the world) uses the term virtual memory as
a synonym for demand paging. Again I consider this unfortunate.
- Demand paging is a fine term and is quite discriptive
- Virtual memory ``should'' be used in contrast with physical
memory to describe any virtual to physical address translation.
** (non-demand) Paging
Simplest scheme to remove the requirement of contiguous physical
memory.
- Chop the program into fixed size pieces called
pages (invisible to the programmer).
- Chop the real memory into fixed size pieces called page
frames or simply frames
(size of a page = size of a frame)
- Sprinkle the pages into the frames
- Keep a table (called the page table) having an
entry for each page. The page table entry or PTE for
page p contains the number of the frame f that contains page p.
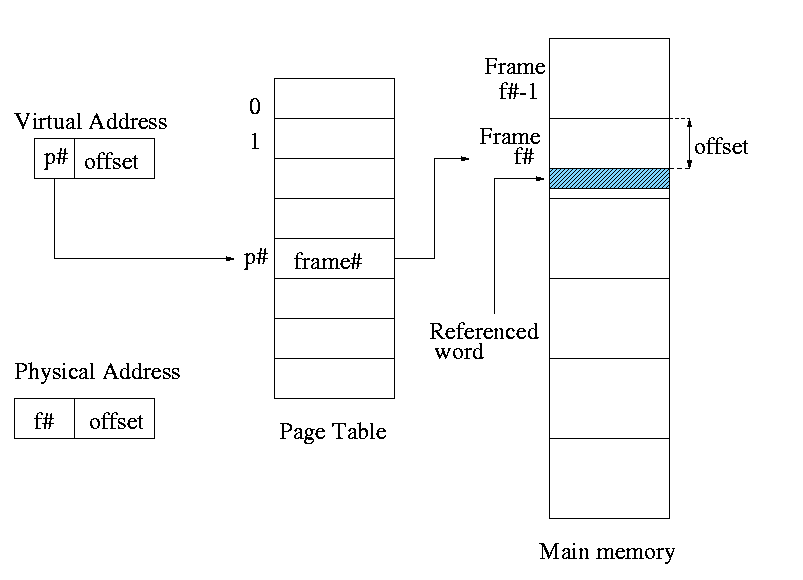
Example: Assume a decimal machine, with
pagesize=framesize=1000.
Assume PTE 3 contains 459.
Then virtual address 3372 corresponds to physical address 459372.
Properties of (non-demand) paging.
- Entire job must be memory resident to run
- No holes, i.e. no external fragmentation.
- If there are 50 frames available and the pagesize is 4KB than a
job requiring <= 200KB will fit, even if the available frames are
scattered over memory.
- Hence (non-demand) paging is useful
- Introduces internal fragmentation approximately equal to 1/2
pagesize
- Still can have a job unable to run due to insufficient memory and
have some memory avail but not enough. This is not called external
fragmentation since it is not due to memory being fragmented.
- Eliminates the placement question. All pages are equally
good since don't have external fragmentation.
- Replacement question unchanged
- Since page boundary occur at ``random'' points and can change from
run to run (the page size can change with no effect on the
program--other than performance, pages are not appropriate units of
memory to use for protection and sharing. This is discussed further
when we introduce segmentation.
Homework: 13
Address translation
- Each memory reference turns into 2 memory references
- Reference the page table
- Reference central memory
- This would be a disaster!
- Hence the MMU caches page#-->frame# translations. This cache is kept
near the processor and can be accessed rapidly
- This cache is called a translation lookaside buffer (TLB) or
translation buffer (TB)
- For the above example, after referencing virtual address 3372,
entry 3 in the TLB would contain 459.
- Hence a subsequent access to virtual address 3881 would be
translated to physical address 459881 without a memory reference.
Choice of page size is discuss below
Homework: 8, 13, 15.
3.2: Virtual Memory (meaning fetch on demand)
Idea is that a program can execute if only the active portion of its
address space is memory resident. That is swap in and swap out
portions of a program. In a crude sense this can be called
``automatic overlays''.
Advantages
- Can run a program larger than the total physical memory.
- Can increase the multiprogramming level since the total size of
the active, i.e. loaded, programs (running + ready + blocked) can
exceed the size of the physical memory.
- Some portions of program are rarely if ever used so inefficient
use of memory to have them loaded
3.2.1: Paging (meaning demand paging)
Fetch pages from disk to memory when they are referenced, with a hope
of getting the most actively used pages in memory.
- Very common: dominates modern operating systems
- Started by the Atlas system at Manchester University in the 60s
(Fortheringham)
- Each PTE continues to have the frame number if the page is
loaded.
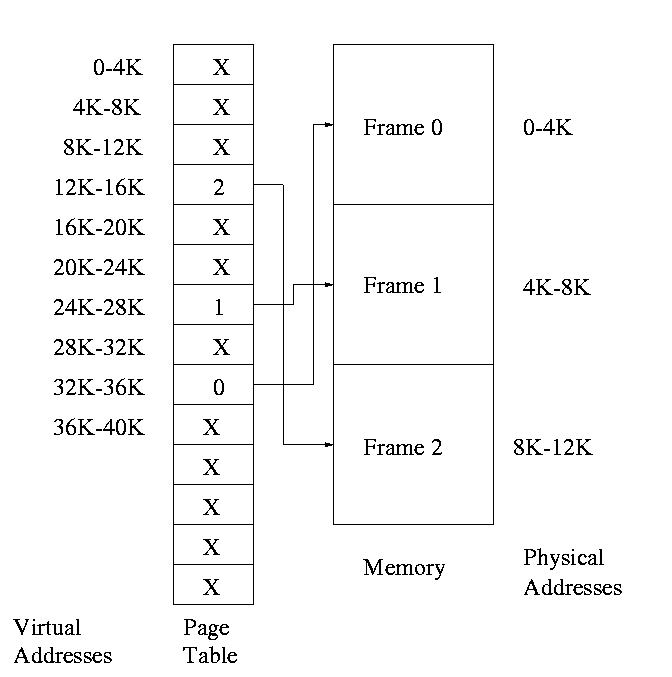
- But what if the page is not loaded (exists only on disk)?
- The PTE has a flag indicating if loaded (can think of the X in
the diagram above as indicating that this flag is not set
- If not loaded, the location on disk is kept in the PTE (not
shown in the diagram)
- When a reference is made to a non-loaded page (sometimes
called a non-existent page, but that is a bad name), the system
has a lot of work to do. We give more details below
- Choose a free frame if one exists
- If not
- choose a victim frame
- More on how to choose later
- Called the replacement question
- write victim back to disk if dirty
- update the victim PTE to show not loaded and where on
disk it has been put (perhaps the disk location is already
there)
- Copy the referenced page from disk to the free frame
- Update the PTE of the referenced page to show that it is
loaded and give the frame number
- Do the std paging address translation (p#,off)-->(f#,off)
- Really not done quite this way
- There is ``always'' a free frame because ...
- There is a deamon active that checks the number of free frames
and if this is too low, chooses victims and ``pages them out''
(writing them back to disk if dirty).
- Size of page table
- Considerations for plain paging apply
- Large pages are good for I/O (providing the data is used)
since it is faster to do one 16KB I/O than four 4KB I/Os and much
faster than sixteen 1KB I/Os
Homework: 11.
3.3.2: Page tables
A discussion of page tables is also appropriate for (non-demand)
paging, but the issues are more acute with demand paging since the
tables can be much larger. Why?
Ans: The total size of the active processes is no longer limited to
the size of physical memory.
Want access to the page table to be very fast since it is needed for
every memory access.
Unfortunate laws of hardware
- Big and fast are essentially imcompatible
- Big and fast and low cost is hopeless
So we can't just say, put the page table in fast processor registers
and let it be huge and sell the system for $1500.
Put the (one-level) page table in main memory.
- Too slow
- TLB would help as mentioned
above (discussed later in more detail).
- Too big
- Currently we are considering contiguous virtual
addresses ranges (i.e. the virtual addresss have no holes).
- Typically put the stack at one end of virtual address and the
global (or static) data at the other end and let them grow towards
each other
- The memory in between is unused.
- This unused memory can be huge (in address range) and hence
the page table will mostly contain unneeded PTEs
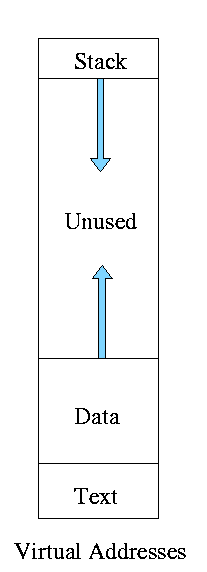
- Works fine if the virtual address range possible is small, which
was once true but no longer (e.g. of PDP-11 in tanenbaum).
Multilevel page tables
Idea, which is also used in unix inode-based file systems, is to add a
level of indirection and have a page table containing pointers to page
tables.
- Imagine one big page table.
- Call it the second level page table and
cut it into pieces each the size of a page.
Note that you can get many PTEs in one page so you will have far
fewer of these pages than PTEs
- Now construct a first level page table containing PTEs that point to
these pages.
- This first level PT is small enough to store in memory.
- But since we still have the 2nd level PT, we have made the world
bigger not smaller!
- Don't store in memory the 2nd level page tables all of whose PTEs
point to unused memory. That is use demand paging on the (first
level page table
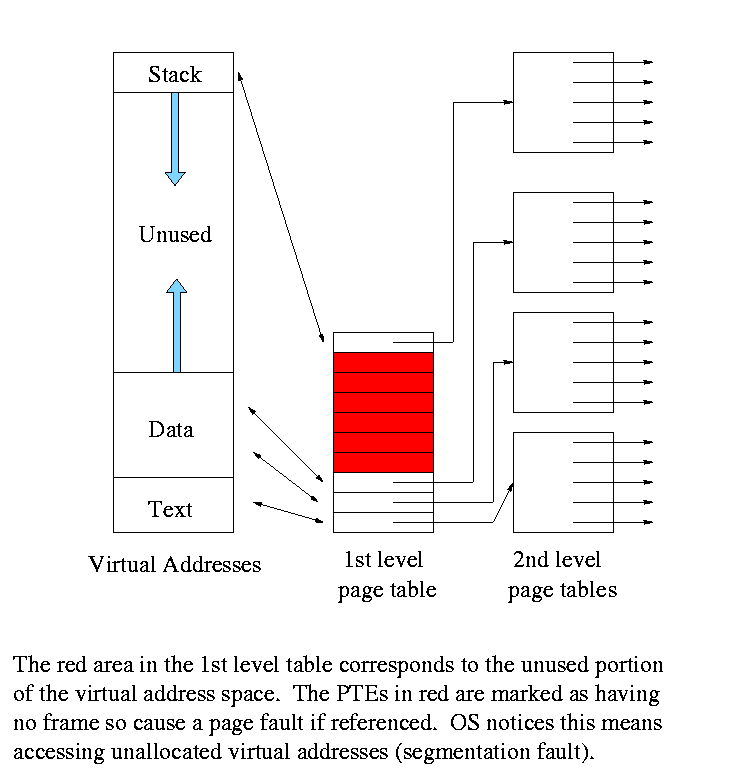
Do an example on the board
The VAX used a 2-level page table structure, but with some wrinkles
(see tanenbaum for details).
Naturally, there is no need to stop at 2 levels. In fact the sparc
has 3 levels and the motorola 68030 has 4 (and the number of bits of
Virtual Address used for P#1, P#2, P#3, and P#4 can be varied).
3.3.4: Associative memory (TLBs)
Note:
Tanenbaum suggests that ``associative memory'' and ``translation
lookaside buffer'' are synonyms. This is wrong. Associative memory
is a general structure and translation lookaside buffer is a special
case.
An
associative memory is a content addressable
memory. That is you access the memory by giving the value
of some field and the hardware searches all the records and returns
the record whose field contains the requested value.
For example
Name | Animal | Mood | Color
======+========+==========+======
Moris | Cat | Finicky | Grey
Fido | Dog | Friendly | Black
Izzy | Iguana | Quiet | Brown
Bud | Frog | Smashed | Green
If the index field is Animal and Iguana is given, the associative
returns
Izzy | Iguana | Quiet | Brown
A Translation Lookaside Buffer
or TLB
is an associate memory
where the index field is the page number. The other fields include
the frame number, dirty bit, valid bit, and others.