
When done on one computer this is the microkernel approach in which the microkernel just supplies interprocess communication and the main OS functions are provided by a number of usermode processes.
This does have advantages. For example an error in the file server cannot corrupt memory in the process server. This makes errors easier to track down.
But it does mean that when a (real) user process makes a system call there are more switches from user to kernel mode and back. These are not free.
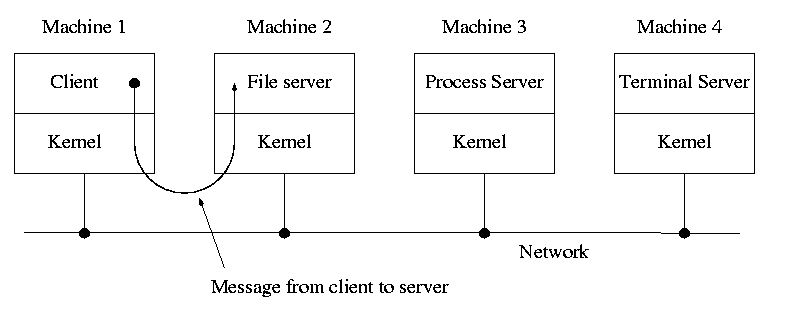
A distributed system can be thought of as an extension of the client server concept where the servers are remote.
Homework: 11
Tanenbaum's chapter title is ``processes''. I prefer process management. The subject matter is process scheduling, interrupt handling, and IPC (Interprocess communication--and coordination).
Definition: A process is a program in execution.
Even though in actuality there are many processes running at once, the OS gives each process the illusion that it is running alone.
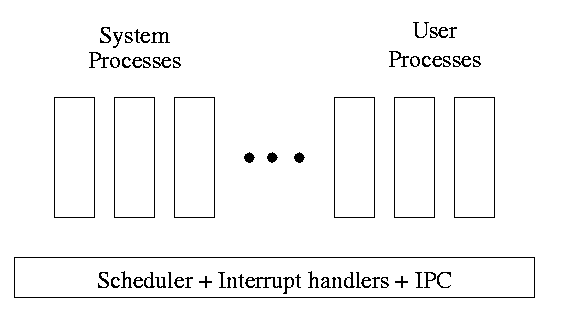
Some systems have user processes and system processes. The latter act as servers satisfying requests from the former (which act as clients). The natural structure of such a system is to have process management (i.e. process switching, interrupt handling, and IPC) in the lowest layer and have the rest of the OS consist of system processes.
This is called the client-server model and is one tanenbaum likes. Indeed, there was reason to believe that it would dominate. But that hasn't happened as yet. One calls such an OS server based. Systems like traditional unix or linux can be called self-service in that the user process itself switches to kernel mode and performs the system call. That is, the same process changes back and forth from/to user<-->system mode and services itself.
Modern general purpose operating systems permit a user to create (and distroy) processes. In unix this is done by the fork system call which creates a child process. Both parent and child keep running (indeed they have the same program text) and each can fork off other processes. A process tree results. The root of the tree is a special process created by the OS during startup.
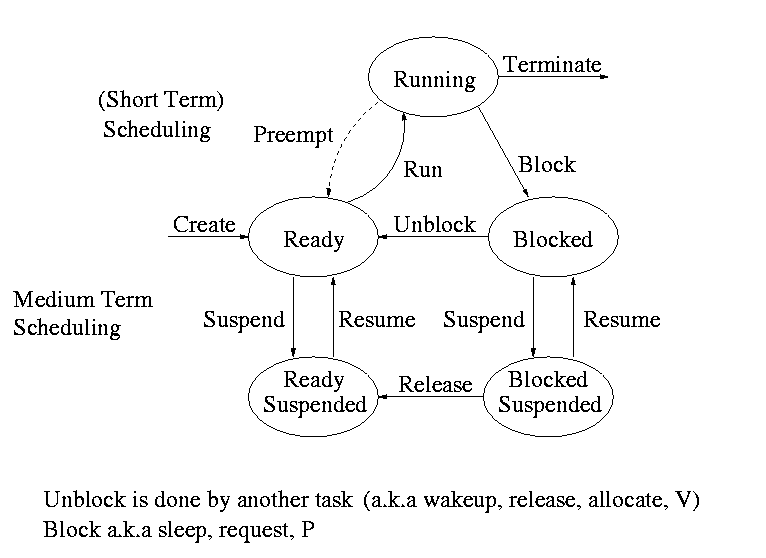
This diagram contains a great deal of information.
One can organize an OS around the scheduler.
Process table
In a well defined location in memory (specified by the hardware) the OS store aninterrupt vector, which contains the address of the (first level) interrupt handler.
Assume a process P is running and an interrupt occurs (say a disk interrupt for the completion of a disk read previously issued by process Q). Note that the interrupt is unlikely to be for process P.
A race condition occurs when two processes can interact and the outcome depends on the order in which the processes execute.
Prevent interleaving of sections of code that need to be atomic with respect to each other. That is, the conflicting sections need mutual exclusion. If process A is executing its critical section, it excludes process B from executing its critical section. Conversely if process B is executing is critical section, it excludes process A from executing its critical section.
Goals for a critical section implementation.
The operating system can choose not to preempt itself. That is, no preemption for system processes (if the OS is client server) or for processes running in system mode (if the OS is self service)
But this is not adequate
Initially P1wants=P2wants=false
Code for P1 Code for P2
Loop forever { Loop forever {
P1wants <-- true ENTRY P2wants <-- true
while (P2wants) {} ENTRY while (P1wants) {}
critical-section critical-section
P1wants <-- false EXIT P2wants <-- false
non-critical-section } non-critical-section }
Explain why this works.
But it is wrong! Why?
Initially turn=1
Code for P1 Code for P2
Loop forever { Loop forever {
while (turn = 2) {} while (turn = 1) {}
critical-section critical-section
turn <-- 2 turn <-- 1
non-critical-section } non-critical-section }
This one forces alternation, so is not general enough.
In fact, it took years (way back when) to find a correct solution. The first one was found by dekker. It is very clever, but I am skipping it (I cover it when I teach OS II).
Initially P1wants=P2wants=false and turn=1
Code for P1 Code for P2
Loop forever { Loop forever {
P1wants <-- true P2wants <-- true
turn <-- 2 turn <-- 1
while (P2wants and turn=2) {} while (P1wants and turn=1) {}
critical-section critical-section
P1wants <-- false P2wants <-- false
non-critical-section non-critical-section
This is Peterson's solution. When it was published, it was a surprise to see such a simple soluntion. In fact Peterson gave a solution for any number of processes. Subsequently, algorithms with better fairness properties were found (e.g. no task has to wait for another task to enter the CS twice). We will not cover these.
Now implementing a critical section for any number of processes is trivial.
while (TAS(s)) {} ENTRY
s<--false EXIT
Note: Tanenbaum does both busy waiting (like above) and blocking (process switching) solutions. We will only do busy waiting.
Homework: 3
The entry code is often called P and the exit code V (tanenbaum only uses P and V for blocking, but we use it for busy waiting). So the critical section problem is to write P and V so that
loop forever
P
critical-section
V
non-critical-section
satisfies
Note that I use indenting carefully and hence do not need (and sometimes omit) the braces {}
A binary semaphore abstracts the TAS solution we gave for the critical section problem.
while (S=closed)
S<--closed <== This is NOT the body of the while
where finding S=open and setting S<--closed is atomic
So for any number of processes the critical section problem can be solved by
loop forever
P(S)
CS <== critical-section
V(S)
NCS <== non-critical-section
The only solution we have seen for arbitrary number of processes is with test and set.
To solve other coordination problems we want to extend binary semaphores
The solution to both of these shortcomings is to remove the restriction to a binary variable and define a generalized or counting semaphore.
while (S=0)
S--
where finding S>0 and decrementing S is atomic
These counting semaphores can solve what I call the semi-critical-section problem, where you premit up to k processes in the section. When k=1 we have the original critical-section problem.
initially S=k
loop forever
P(S)
SCS <== semi-critical-section
V(S)
NCS