======== START LECTURE #22
========
Performance example to do on the board (dandy exam question).
-
Assume
-
5% I-cache miss
-
10% D-cache miss
-
1/3 of the instructions access data
-
CPI = 4 if miss penalty is 0 (A 0 miss penalty is not
realistic of course)
-
What is CPI with miss penalty 12 (do it)?
-
What is CPI if double speed cpu+cache, single speed mem
(24 clock miss penalty) (do it)?
-
How much faster is the ``double speed'' machine? It would be double
speed if miss penalty 0 or 0% miss rate
Homework:
7.15, 7.16
A lower base (i.e. miss-free) CPI makes stalls appear more expensive
since waiting a fixed amount of time for the memory corresponds to
losing more instructions if the CPI is lower.
Faster CPU (i.e., a faster clock) makes stalls appear more expensive
since waiting a fixed amount of time for the memory corresponds to
more cycles if the clock is faster (and hence more instructions since
the base CPI is the same).
Another performance example
- Assume
- I-cache miss rate 3%
- D-cache miss rate 5%
- 40% of instructions reference data
- miss penalty of 50 cycles
- Base CPI of 2
- What is the CPI including the misses?
- How much slower is the machine when misses are taken into account?
- Redo the above if the I-miss penalty is reduced to 10 (D-miss
still 50)
- With I-miss penalty back to 50, what is performance if CPU (and the
caches) are 100 times faster
Remark: Larger caches have longer hit times.
Improvement: Associative Caches
Consider the following sad story. Jane had a cache that held 1000
blocks and had a program that only references 4 (memory) blocks,
namely 23, 1023, 123023, and 7023. In fact the reference occur in
order: 23, 1023, 123023, 7023, 23, 1023, 123023, 7023, 23, 1023,
123023, 7023, 23, 1023, 123023, 7023, etc. Referencing only 4 blocks
and having room for 1000 in her cache, Jane expected an extremely high
hit rate for her program. In fact, the hit rate was zero. She was so
sad, she gave up her job as webmistriss, went to medical school, and
is now a brain surgeon at the mayo clinic in rochester MN.
-
So far We have studied only direct mapped caches,
i.e. those for which the location in the cache is determined by
the address. Since there is only one possible location in the
cache for any block, to check for a hit we compare one
tag with the HOBs of the addr.
-
The other extreme is fully associative.
-
A memory block can be placed in any cache block
-
Since any memory block can be in any cache block, the cache index
where the memory block is store tells us nothing about which
cache block is here. Hence the tag must be entire address and
we must check all cache blocks to see if we have a hit.
-
The larger tag is a minor problem.
-
The search is a disaster.
- It could be done sequentially (one cache block at a time),
but this is much too slow.
- We could have a comparator with each tag and mux
all the blocks to select the one that matches.
- This is too big due to both the many comparators and
the humongous mux.
- However, it is exactly what is done when implementing
translation lookaside buffers (TLBs), which are used with
demand paging
-
An alternative is to have a table with one entry per
MEMORY block giving the cache block number. This is too
big and too slow for caches but is used for virtual memory
(demand paging).
-
Most common for caches is an intermediate configuration called
set associative or n-way associative (e.g. 4-way
associative) or n-way set associative.
- n is typically 2, 4, or 8.
- If the cache has B blocks, we group them into B/n
sets each of size n. Memory block number K is
then stored in set K mod (B/n).
- Figure 7.15 has a bug. It indicates that the tag for memory
block 12 is itself 12. The figure below corrects this
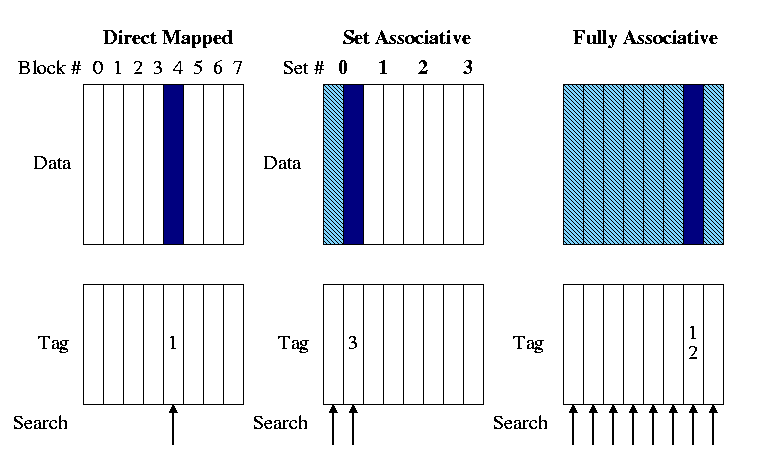
-
The picture did 2-way set set associative. Do on the board
4-way set associative.
-
The Set# = (memory) block# mod #sets
-
The Tag = (memory) block# / #sets
-
What is 8-way set associative in a cache with 8 blocks (i.e., the
cache in the picture)?
-
What is 1-way set associative?
-
Why is set associativity good? For example, why is 2-way set
associativity better than direct mapped?
-
Consider referencing two modest arrays (<< cache size) that
start at location 1MB and 2MB.
-
Both will contend for the same cache locations in a direct
mapped cache but will fit together in a cache with >=2 sets.