======== START LECTURE #20
========
Chapter 7 Memory
Homework:
Read Chapter 7
Ideal memory is
-
Fast
-
Big (in capacity; not physical size)
-
Cheap
-
Imposible
We observe empirically
-
Temporal Locality: The word referenced now is likely to be
referenced again soon. Hence it is wise to keep the currently
accessed word handy for a while.
-
Spacial Locality: Words near the currently referenced
word are likely to be referenced soon. Hence it is wise to
prefetch words near the currently referenced word and keep them
handy for a while.
So use a memory hierarchy
-
Registers
-
Cache (really L1 L2 maybe L3)
-
Memory
-
Disk
-
Archive
There is a gap between each pair of adjacent levels.
We study the cache <---> memory gap
-
In modern systems there are many levels of caches.
-
Similar considerations apply to the other gaps (e.g.,
memory<--->disk, where virtual memory techniques are applied)
-
But terminology is often different, e.g. cache line vs page.
-
In fall 97 my OS class was studying ``the same thing'' at this
exact point (memory management). Not true this year since the OS
text changed and memory management is earlier.
A cache is a small fast memory between the
processor and the main memory. It contains a subset of the contents
of the main memory.
A Cache is organized in units of blocks. Common
block sizes are 16, 32, and 64 bytes.
-
We also view memory as organized in blocks as well. If the block
size is 16, then bytes 0-15 of memory are in block 0, bytes 16-31
are in block 1, etc.
-
Transfers from memory to cache and back are one block.
-
Big blocks make good use of spacial locality
-
(OS think of pages and page frames)
A hit occurs when a memory reference is found in
the upper level of memory hierarchy.
-
We will be interested in cache hits (OS in page hits), when the
reference is found in the cache (OS: when found in main memory)
-
A miss is a non-hit.
-
The hit rate is the fraction of memory references
that are hits.
-
The miss rate is 1 - hit rate, which is the
fraction of references that are misses.
-
The hit time is the time required for a hit.
-
The miss time is the time required for a miss.
-
The miss penalty is Miss time - Hit time.
We start with a very simple cache organization.
-
Assume all referencess are for one word (not too bad).
-
Assume cache blocks are one word.
-
This does not take advantage of spacial locality so is not
done in real machines.
-
We will drop this assumption soon.
-
Assume each memory block can only go in one specific cache block
-
Called Direct Mapped.
-
The location of the memory block in the cache (i.e. the block
number in the cache) is the memory block number modulo the
number of blocks in the cache.
-
For example, if the cache contains 100 blocks, then memory
block 34452 is stored in cache block 52.
-
In real systems the number of blocks in the cache is a power
of 2 so taking modulo is just extracting low order bits.
-
Example: if the cache has 16 blocks, the location of a block in
the cache is the low order 4 bits of block number.
- A pictorial example for a cache with only 4 blocks and a memory
with only 16 blocks.
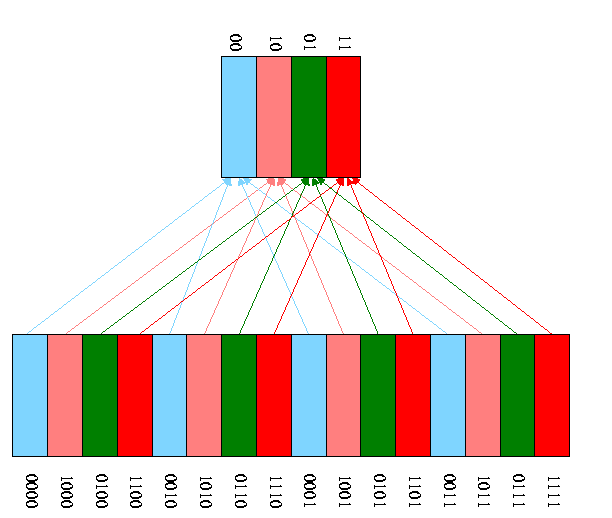
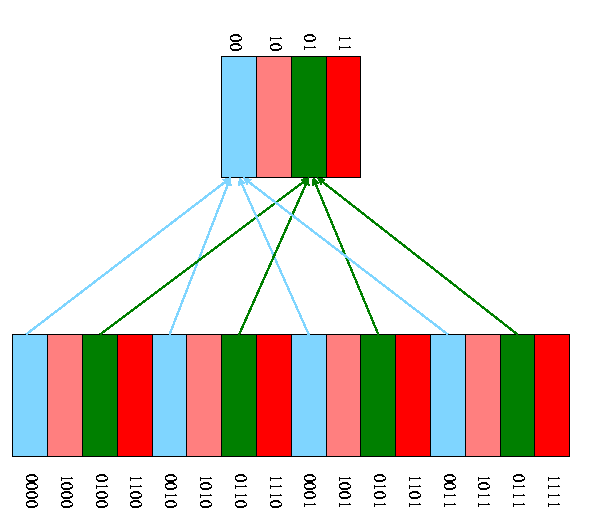
-
How can we tell if a memory block is in the cache?
-
We know where it will be if it is there at all
(memory block number mod number of blocks in the cache).
- But many memory blocks are assigned to that same cache block.
-
So we need the ``rest'' of the address (i.e., the part lost
when we reduced the block number modulo the size of the cache)
to see if the block in the cache is the memory block of
interest,
-
Store the rest of the address, called the tag.
-
Also store a valid bit per cache block so that we
can tell if there is a memory block stored in this cache
block.
For example when the system is powered on, all the cache
blocks are invalid.
Example on pp. 547-8.
- Tiny 8 word direct mapped cache with block size one word and all
references are for a word.
- In the table to follow all the addresses are word addresses. For
example the reference to 3 means the reference to word 3 (which
includes bytes 12, 13, 14, and 15).
- If reference experience a miss and the cache block is valid, the
current reference is discarded (in this example only) and the new
reference takes its place.
- Do this example on the board showing the address store in the
cache at all times
| Address(10) | Address(2) | hit/miss | block# |
|---|
| 22 | 10110 | miss | 110 |
| 26 | 11010 | miss | 010 |
| 22 | 10110 | hit | 110 |
| 26 | 11010 | hit | 010 |
| 16 | 10000 | mis | 000 |
| 3 | 00011 | miss | 011 |
| 16 | 10000 | hit | 000 |
| 18 | 10010 | miss | 010 |
The basic circuitry for this simple cache to determine hit or miss
and to return the data is quite easy.
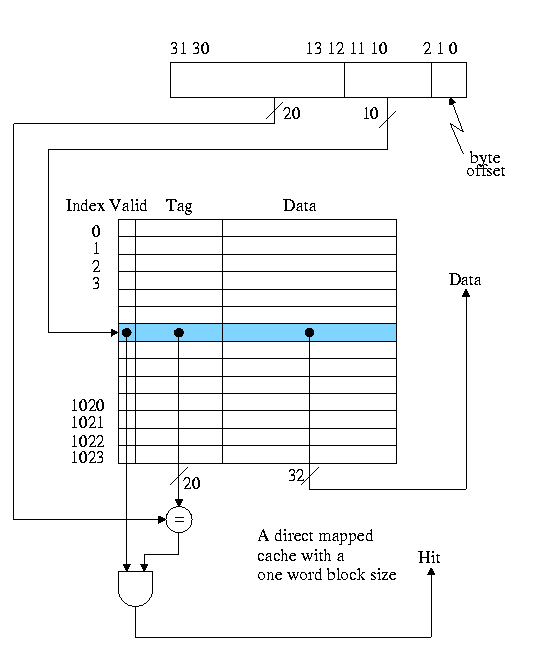
Calculate on the board the total number of bits in this cache.
Homework:
7.1 7.2 7.3
Processing a read for this simple cache
-
Hit is trivial (return the data found).
-
Miss: Evict and replace
- Why? I.e., why keep new data instead of old?
Ans: Temporal Locality
- This is called write-allocate.
- The alternative is called write-no-allocate.
Skip section ``handling cache misses'' as it discusses the
multicycle and pipelined implementations of chapter 6, which we
skipped.
For our single cycle processor implementation we just need to note
a few points
- The instruction and data memory are replaced with caches.
- On cache misses one needs to fetch or store the desired
data or instruction in central memory.
- This is very slow and hence our cycle time must be very
long.
- Yet another reason why the single cycle implementation is
not used in practice.
Processing a write for this simple cache
-
Hit: Write through vs write back.
-
Write through writes the data to memory as well as to the cache.
-
Write back: Don't write to memory now, do it
later when this cache block is evicted.
-
Miss: write-allocate vs write-no-allocate
-
The simplist is write-through, write-allocate
-
Still assuming blksize=refsize = 1 word and direct mapped
-
For any write (Hit or miss) do the following:
-
Index the cache using the correct LOBs (i.e., not the very
lowest order bits as these give the byte offset.
-
Write the data and the tag
- For a hit, we are overwriting the tag with itself.
- For a miss, we are performing a write allocate and
since the cache is write-throught we can simply overwrite
the current entry
-
Set Valid to true
-
Send request to main memory
-
Poor performance
-
GCC benchmark has 11% of operations stores
-
If we assume an infinite speed memory, CPI is 1.2
for some reasonable estimate of instruction speeds
-
Assume a 10 cycle store penalty (reasonable) since we have
to write main memory (recall we are using a write-through
cache).
-
CPI becomes 1.2 + 10 * 11% = 2.5, which is
half speed.