K-means-cluster (in S : set of vectors : k : integer)
{ let C[1] ... C[k] be a random partition of S into k parts;
repeat {
for i := 1 to k {
X[i] := centroid of C[i];
C[i] := empty
}
for j := 1 to N {
X[q] := the closest to S[j] of X[1] ... X[k]
add S[j] to C[q]
} }
until the change to C (or the change to X) is small enough.
}
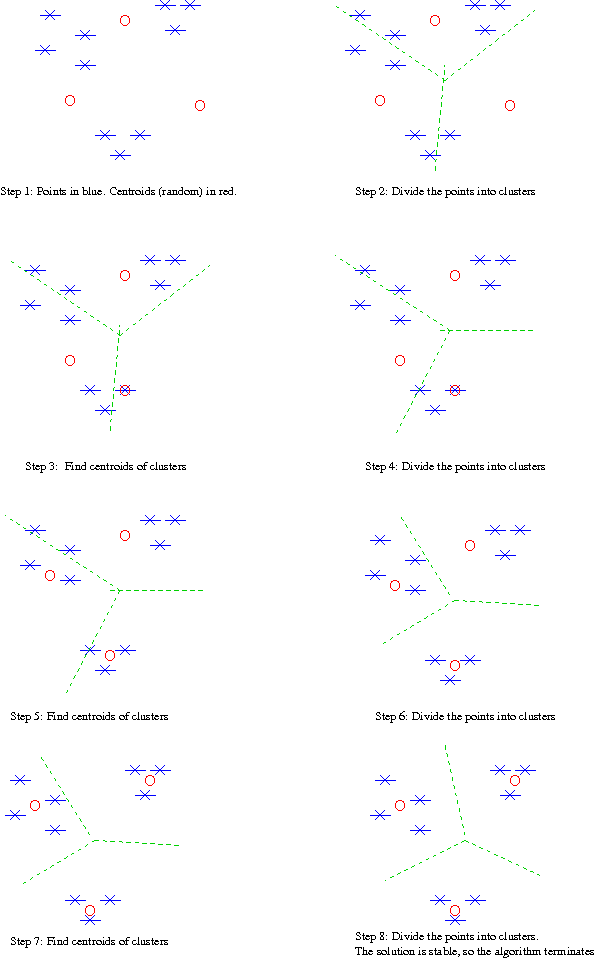
Example: (Note: I have started here with random points rather than a random partition.)
Features:
Sum of the squared distance steadily decreases over the iterations.
Hill-climbing algorithm.
Problems:

Variant 1: Update centroids incrementally. Claims to give better results.
Variant 2: Bisecting K-means algorithm:
for I := 1 to K-1 do {
pick a leaf cluster C to split;
for (J := 1 to ITER)
use 2-Means clustering to split C into two subclusters C1 and C2;
choose the best of the above splits and make it permanent
}
Generates a binary clustering hierarchy. Works better (so claimed) than
K-means.
Variant 3: Allow overlapping clusters: If distances from P to C1 and to C2 are close enough then put P in both clusters.
First, the computation of the new centroid requires only the points added to the cluster, the points taken out of the cluster, and the number of points in the cluster.
Second, computing the change made to the cluster made by moving the centroid can be made more efficient as follows:
Let XJ(T) be the centroid of the Jth cluster on the Tth iteration,
and let VI be the Ith point. Note that
dist(VI,XJ(T+1)) <=
dist(VI,XJ(T)) +
dist(XJ(T),XJ(T+1).)
Therefore you can maintain two arrays:
RADIUS(J) = an overestimate of the maximum value of dist(VI,XJ), where VI is in cluster J.
DIST(J,Z) = an underestimate of the minimum value of dist(VI,XZ), where VI is in cluster J.
which you update as follows:
RADIUS(J) := RADIUS(J) + dist(XJ(T),XJ(T+1));
DIST(J,Z) := DIST(J,Z) - dist(XZ(T),XZ(T+1))
- dist(XJ(T),XJ(T+1));
then as long as RADIUS(J) < DIST(J,Z) you can be sure that none of
the points in cluster J should be moved to cluster Z. (You update these
values more exactly whenever a point is moved.)
This can be approximated in linear time as follows:
medoid(C,X) {
U := the point in C furthest from X;
V :- the point in C furthest from U;
Y := the point in C that minimizes d(Y,U) + d(Y,V) + |d(Y,U)-d(Y,V)|
return(Y)
}
Note that
d(X,U)+d(X,V) is minimal, and equal to d(U,V) for points X on the line
between U and V, and for points on that line |d(X,U)-d(X,V)| is minimal
when X is at the center of the line.
[Geraci et al. 2006] call this the "medoid" of C.
For K=1,2, ... compute SK = best system with K clusters.
Plot RSS(SK) vs. K.
Look for a "knee" in plot. Choose that as value of K.
Question to which I don't know the answer: Is this curve always concave
upward?