S -> NP VP NP -> NG | NG "and" NG NG -> pronoun | noun VP -> verb | verb NP | VP "and" VP Lexicon: I : pronoun. cook : noun, verb eggs : noun fish : noun, verb.Which of the following parse tree are correct:
i. S ---> NP ---> NG ---> pronoun ---> I
|
|-> VP ---> verb ---> cook
|
|-> NP ---> NG ---> noun ---> eggs
|
|-> "and"
|
|-> NG ---> noun ---> fish
ii. S ---> NP ---> NG ---> pronoun ---> I
|
|-> VP ---> verb ---> cook
|
|-> NP ---> NG ---> noun ---> eggs
|
|-> "and"
|
|-> VP ---> verb ---> fish
iii.S ---> NP ---> NG ---> pronoun ---> I
|
|-> VP ---> VP ---> verb ---> cook
| |
| |-> NP ---> NG ---> noun ---> eggs
|
|-> "and"
|
|-> VP ---> verb ---> fish
iv. S ---> NP ---> NG ---> pronoun ---> I
|
|-> VP ---> verb ---> cook
|
|-> NP ---> NG ---> noun ---> eggs
|
|-> "and"
|
|-> VP ---> verb ---> fish
A. All four. Answer: D.
Answer: E.
Answer: A.
Answer: D.
Answer: D.
s(X,L) --- Person X speaks language L. c(X,Y) --- Persons X and Y can communicate. i(W,X,Y) --- Person W can serve as an interpreter between persons X and Y. j,p,m,e,f --- Constants: Joe, Pierre, Marie, English, and French respectively.
A. Express the following statements in Z:
B. Show how sentences (i), (ii), (iii), (v), and (vi) can be expressed in Datalog. (Hint: Sentences (i) and (v) each turn into two facts in Datalog.)
Answer:
1. s(j,e).
2. s(p,f).
3. s(X,L) ^ s(Y,L) => c(X,Y).
4. c(W,X) ^ c(W,Y) => i(W,X,Y).
5. s(m,e).
6. s(m,f).
7. i(m,j,p).
C. Explain why sentence (iv) cannot be expressed in Datalog.
Answer: Because Datalog cannot express an existential quantifier.
D. Show how (vi) can be proven from (i), (ii), (iii) and (v) using forward chaining.
Answer:
8. c(m,j). Combining (3) with (5) and (1), substituting X=m, Y=j, L=e.
9. c(m,p). Combining (3) with (6) and (2), substituting X=m, Y=p, L=f.
10. i(m,j,p). Combining (4) with (8) and (9), substituting W=m, X=j, Y=p.
E. Show how (vi) can be proven from (i), (ii), (iii) and (v) using backward chaining.
Goal G0: i(m,j,p). Match with (4) binding W1=m, X1=j, Y1=p.
Subgoals G1: c(m,j). G2: c(m,p).
Goal G1: c(m,j). Match with (3) binding X2=m, Y2=j.
Subgoals G3: s(m,L2). G4: s(j,L2)
Goal G3: s(m,L2). Match with (5) binding L2=e.
G3 succeeds.
Goal G4: s(j,e). Match with (1).
G4 succeeds.
G1 succeeds.
Goal G2: c(m,p). Match with (3) binding X3=m, Y3=p.
Subgoals: G5: s(m,L3). G6: s(p,L3).
Goal G5: s(m,L3). Match with (5) binding L3=e.
G5 succeeds.
Subgoal: G6: s(p,e). No match. G6 fails.
Return to G5.
Goal G5: s(m,L3). Match with (6) binding L3=f.
G5 succeeds.
Subgoal: G6: s(p,f). Match with (2).
G6 succeeds.
G2 succeeds.
G0 succeeds.
Answer: Sentence A can be disambiguated using selectional restrictions: The object of "wore" must have the feature CLOTHES which the meaning "lawsuit" does not have. (Actually, there are other meanings of "wore" -- "She wore a smile", "The lecture wore me out" etc. but none that allows a lawsuit as object.)
Sentence B can be disambiguated using frequency in context. The word "court" establishes a context of legal affairs, in which "suit" probably means a law suit.
Answer:
Morphological analysis identifies the structure of each individual word, separating it into a root word (or words) combined with prefixes, suffixes, and inflections. It is applied to each word separately. The output is a set of morphemes.
Syntactic analysis finds the grammatical structure of each individual sentence, described as a parse tree (plus transformations). The input is a single sentence, plus the output of the morphological analysis on the words of the sentence. The output is a parse tree.
Semantic analysis interprets the meaning of each individual sentence, based on the meanings of the words and the syntax of the sentence. The input is the parse tree constructed by the syntactic analysis. The output is a symbolic representation of the meaning of the sentence.
Discourse/text analysis connects the meanings of the individual sentence to get the overall meaning of the conversation/text.
A. Give an example of a sentence or pair of sentences in which selectional restrictions can be used to disambiguate potential anaphoric ambiguity. Explain the ambiguity and the selectional restriction used.
Answer: There are lots of answers. Here's one. "When I cut the steak with my knife, I found that it was undercooked" (Contrast "... its blade broke off its handle"). "Undercooked" can only modify an object with feature FOOD; hence "it" can be "steak" but not "knife".
B. Give an example of a sentence or pair of sentences in which there is a potential anaphoric ambiguity that cannot be disambiguated using selectional restrictions. Explain why not. Give a method for carrying out the disambiguation.
Answer: "Margaret invited Susan for lunch but she declined." The anaphoric ambiguity of "she" cannot be resolved by selectional restrictions, since Margaret and Susan have all the same features. Rather a rule of world knowledge asserts that if A invites B to do something, then B is likely either to accept or to decline.
Answer:
Problem 10 (10 points)
In this problem and in problem 11, we consider a data set
with three Boolean predictive attributes,
A,B,C, and a Boolean classification, Z.
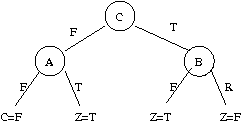
A. Suppose that your data is completely characterized by the following rules:
B. True or false: Given any consistent set of rules like those above, it is possible to construct a decision tree that executes that set of rules. By "consistent", I mean that there are no examples where two different rules give different answers.
Answer: True. At the worst, one can use the complete decision tree, where all tests on all attributes are made, and so each different instance is represented by one leaf.
Problem 11 (5 points)
Which of the following expresses the independence
assumption that is used
in deriving the formula for Naive Bayesian learning, for the classification
problem in problem 3.
Answer: c. (b) is Bayes' Law, which is used, but is not an independence assumption. (d) and (f) are independence assumptions, but not the ones we need. (a) and (e) are junk.
Problem 12 (10 points)
Consider the following data set T. A and B are numerical attributes and
Z is a Boolean classification.
A B Z
1 2 T
2 1 F
3 2 T
1 1 F
Find a set of weights and a threshhold that categorizes all this data correctly. (Hint: Sketch a graph of the instances in the plane where the coordinates are A and B.)
Answer: wA=0, wB=1, T=1.5 will do fine.