
Description: A large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four key concepts of core intuitive psychology: goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs.
Size: 8400 videos. Each video lasts from 5.6 to 25.2 seconds.
Paper
Web site
Examples:
Created using:
********************************************************
Description: Benchmark for compositional spatio-temporal reasoning.
Examples:
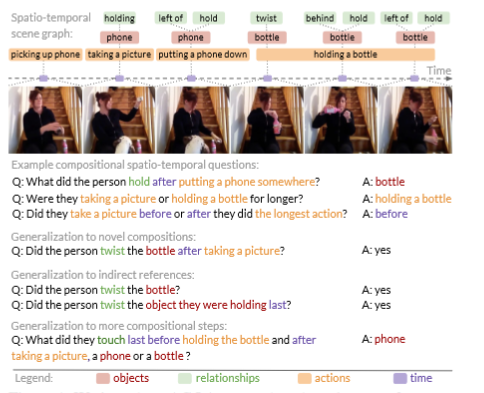
Size: 9600 videos, a balanced subset of 3.9M question-answer pairs, and an unbalanced collection
of 192M question-answer pairs.
Paper
Web site
Created using: The videos are taken from
preexisting datasets of videos annotated with scene graphs: Action
Genome and Charades. The questions are generated synthetically from the scene graphs
********************************************************
Description: A comprehensive suite of tasks probing commonsense psychology.
A collection of cartoons of a toy, two dimensional world, showing an ``agent'' behavior either in accordance with the tenets of commonsense psychology or in violation of those tenets. A human infant exhibits its understanding of the tenet by staring longer, in surprise, at those scenarios that violate commonsense psychology. For AIs, there is a training and a test set of such videos. 288 responses by 11-month old infants have been collected and analyzed.
Examples:

Created using: Synthesized
********************************************************
Description: CATER is a diagnostic dataset for Compositional Actions and TEmporal Reasoning in dynamic tabletop scenes. Three tasks are on the dataset, each with an increasingly higher level of complexity, but set up as classification problems
Examples: Track the position of the balls as the cones move around
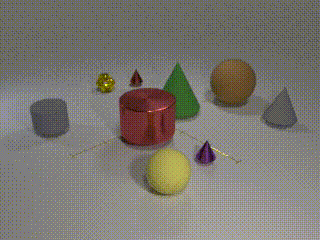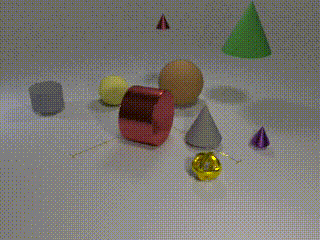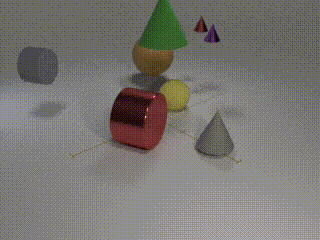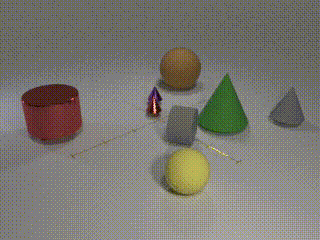
Size: 5500 videos
Paper
Web site
Created using: Synthesized.
********************************************************
Description: CLEVRER is a diagnostic video dataset for systematic evaluation of computational models on a wide range of reasoning tasks. It includes four types of questions: descriptive (e.g., "what color"), explanatory ("what is responsible for"), predictive ("what will happen next"), and counterfactual ("what if").
Size: Training set: 10K videos. Validation set:5K videos. Test set:
5K videos.
Paper
Web site
Created using: Synthesized
Examples:
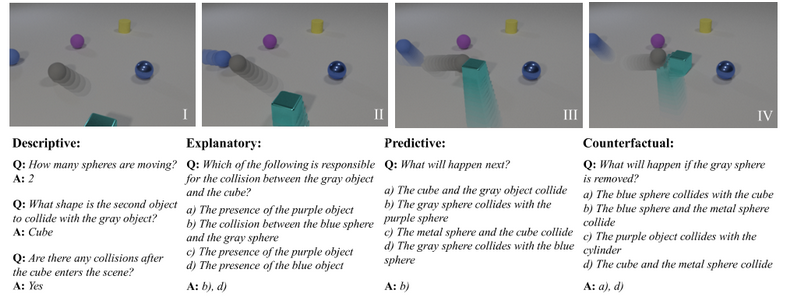
********************************************************
Description: The COPHY dataset consists of three scenarios. Each scenario consists of (a) an observed sequence , a counterfactual sequence, and an intervention. The observed and counterfactual sequences are 6 second snippets of synthesized video.
Size: 3 scenarios. 286,000 experiments.
Paper
Website
Created using: Synthesized video
Examples:
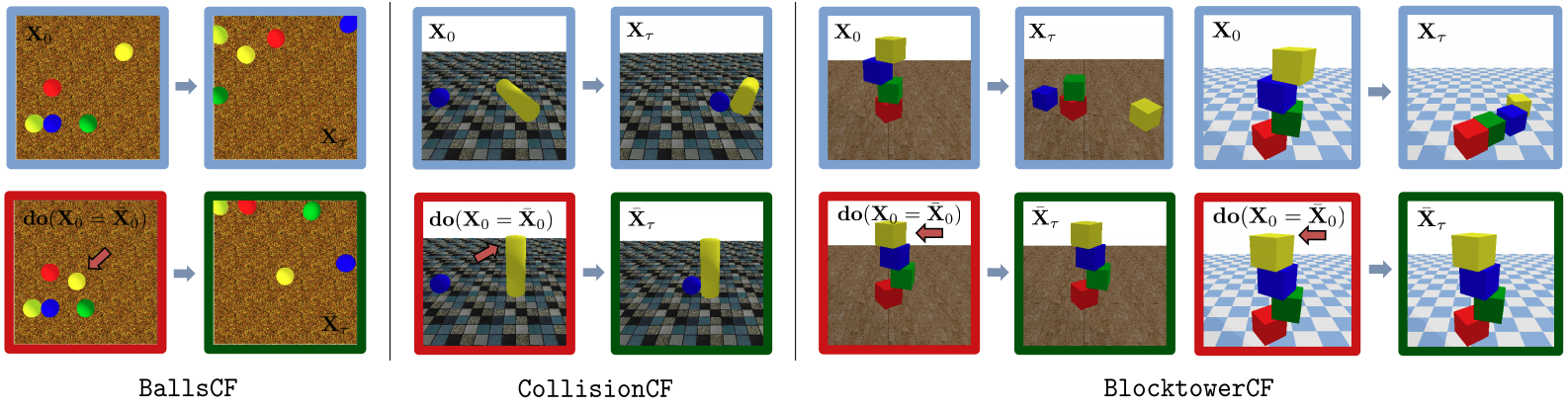
******************************************************
Description: The system views a video. The system should indicate "surprised" if the scene seems to be physically implauible, but not if it is plausible. This is modelled on studies of physical reasoning in pre-verbal infants.
Examples: See examples at this link. It is not very feasible to embed them here.
Size: 5772 videos.
Paper
Web site
Created using: Synthesized
********************************************************
Description: IntPhys is a benchmarks for intuitive physics, showing a mixture of physically possible and physically impossible scenarios.
Size: Training set has 15K videos, 7 seconds each.
Paper
Web site
Created using: Synthesized video.
Examples:

********************************************************
Description: Question-answer pairs about physical situations where both visual and audio information must be used.
Size: 13,400 QA pairs: 1526 videos and 1377 unique questions.
Paper
Github
Created using: Videos were collected from YouTube. Filtering and question/answer generation was done by human annotators --- mostly from MTurk but, for some specific tasks, in-house experts.
Examples:
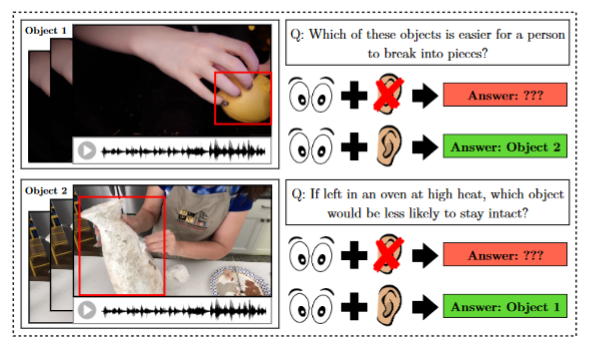
********************************************************
Description Predicting whether object A will touch object B in eight different physical situations.
Example: The question is, "Will the red object touch the yellow
object?

Size: 1200 stimuli (8 categories of physical scenarios; 150 stimuli
per category.)
Paper
Github
Created using: Synthesized.
********************************************************
Description Short videos (2-6 seconds) of actions labelled with a description.
Size: 220K videos
Paper
Web site
Created using: Crowdworkers created both the videos and the labels.
Examples:

********************************************************
Description: an open-ended commonsense video question-answering task, where we ask questions about the intents, effects and attributes of the agents in the video.
Examples:

Size: 1500 videos and 37,000 questions.
Paper
Github
Created using: Crowd-sourcing