
Description: The task is (I think) given an image from a cooking video showing an action in progress, predict some aspects of what has happened and what will happen: A textual description, an action-object pair, effects, high-level goals preconditions, preceding events, and succeeding events.
Examples:
Size: 8522 images. 59,300 inferences.
Paper
GitHub
Created using: Images are frames from cooking videos in
the dataset YouCook2. Annotations are generated automatically using information
from YouCook2.
******************************************************
Description: A large-scale VQA benchmark, collected iteratively via an adversarial human-and-model-in-the-loop procedure.
Examples:
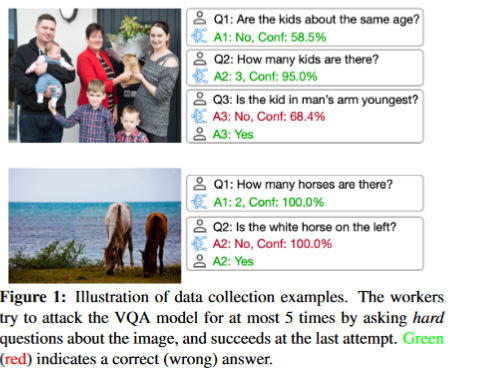
Size: 81,000 images. 150,000 human-verified adversarial questions. 1.5M human-written answers.
Paper
Web site
Created using: Images collected from pre-existing datasets.
Questions and answers generated by gamification, using
an adversarial human-and-model-in-the-loop procedure with crowd workers.
******************************************************
Description: An example in COFAR consists of a query, an image, a visual named entity, a commonsense (general) fact, and a fact about a specific named entity. The named entity can be either either a landmarks (e.g. the Eiffel Tower), a celebrity, or a brand. The task is to find an image corresponding to a query.
Examples:

Size: 40,797 queries; 25,297 images.
Paper.
Github
Created using: Images are from existing online datasets.
Named-entity information was gathered from Wikipedia. Annotations were done
by three annotators.
********************************************************
Description: Each instance consists an image, a commonsense question with a response, a description of a counterfactual change, a new response to the question, and three distractor responses.
Example:

Size: 3500 instances.
Github.
Paper
Created using: Crowd sourcing
********************************************************
Example:

Size: 150 examples, each example being a pair of prompts.
Paper
Github
Created using: Manually curated by experts, based on suggestions elicited
from GPT-4.
********************************************************
Description: A benchnark for visual question answering involving commonsense and compositional reasoning.
Examples:
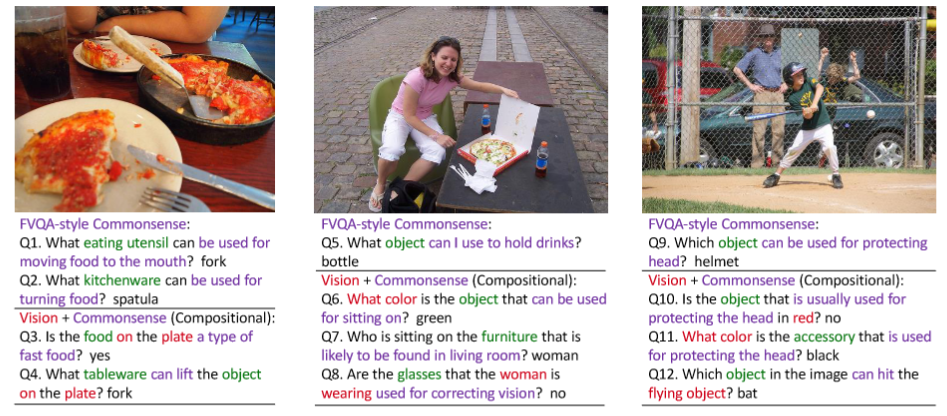
Size: 96,000 images. 494,000 questions.
Paper
Github
Created using: Images are from Visual Genome. Questions are synthesized, combining Scene Graph annotations
with information in ConceptNet.
********************************************************
Description: A large-scale dataset for visual-textual entailment with NLEs.
Examples:

Size: 430,000 instances
Paper
Github
Created using: Synthesized from the SNLI-VE dataset.
********************************************************
Description: A visual question answering database which requires external commonsense knowledge to answer.
Examples:

Size: 2190 images.
Paper
Github
Created using: Images are taken from COCO and ImageNet datasets. Questions are synthesized by combining
the information associated with the images with knowledge is datasets such as ConceptNet, DBpedia, and WebChild.
********************************************************
Description: GD-VCR includes 328 images, which are mainly sourced from movies and TV series in East Asian, South Asian, African, and Western countries. The images are paired with 886 QA pairs, which need to be answered with geo-diverse commonsense and thorough understanding of the images.
Examples:

Size: 328 images, 886 QA pairs.
Paper
Github
Created using: All parts of the dataset construction, including image collection, are done by expert annotators.
********************************************************
Description: There are three benchmarks: In the Image-to-Label benchmark, half of an image is shown, and the task is to choose (multiple choice) an object that is likely to be in the other half. In the Label-to-Image benchmark, the name of an object is given, and the task is to choose among several half-images the one that is most likely to contain the object in the missing half. In the Image-to-Image benchmark, one cropped image I and a collection C of cropped images are shown, and the task it to identify which of the images in C was cropped from the same scene as I.
Examples:

Size: 126,000 examples.
Paper
Benchmark not available online
Created using: Synthesized from MS-COCO
******************************************************
Description Find a person satisfying a description in an image.
Examples:
Size: 67,000 images; 130,000 descriptions.
Paper
Github
Created using: Extracted from VCR; refined with crow-workers.
********************************************************
Description: A benchmark for evaluating explainable and high-order visual question reasoning ability with three distinguishable merits: 1) the questions often contain one or two relationship triplets, which requires the model to have the ability of multistep reasoning to predict plausible answers; 2) we provide an explicit evaluation on a multistep reasoning process that is constructed with image scene graphs and commonsense knowledge bases; and 3) each relationship triplet in a large-scale knowledge base only appears once among all questions.
Examples:
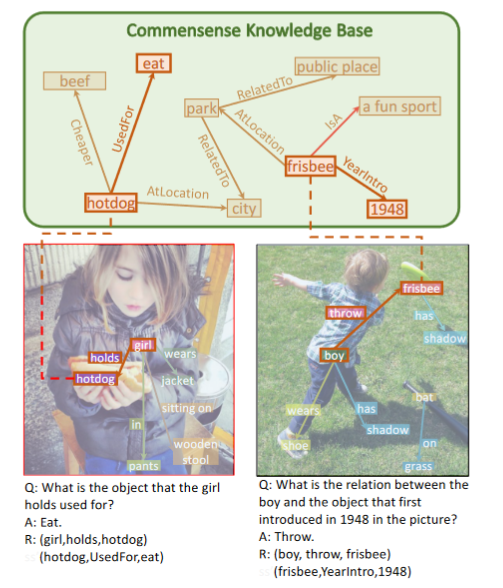
Size: 33,000 images; 157,000 Q/A pairs
Paper
Not available online
Created using: Synthesized, combining images in Visual Genome with
facts in WebChile, ConceptNet, and DBPedia.
********************************************************
Description: A large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank.
Examples:
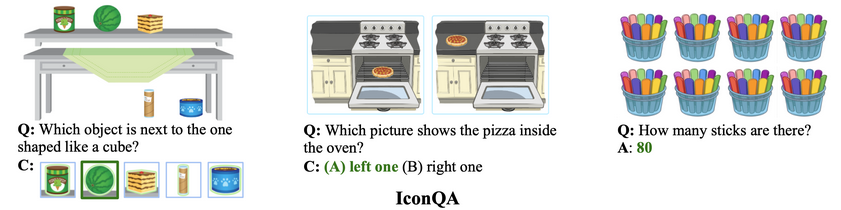
Size: 107,400 instances.
Paper
Github
Created using: Images collected from math textbooks. The questions were written by crowd workers.
********************************************************
Description: Match an image (multiple choice) to an idiom, metaphor, or simile.
Example: 
Size: Idioms: 628 texts and 6697 images. Similes: 142 texts and
2923 images. Metaphors: 35 texts and 1062 images.
Paper
Github
Constructed using:
Texts collected from pre-existing collections. Images collected by
web search and filtered and validated by crowd-workers
********************************************************
Description: A visual question answering database which requires higher-level knowledge and explicit reasoning to answer.
Examples:
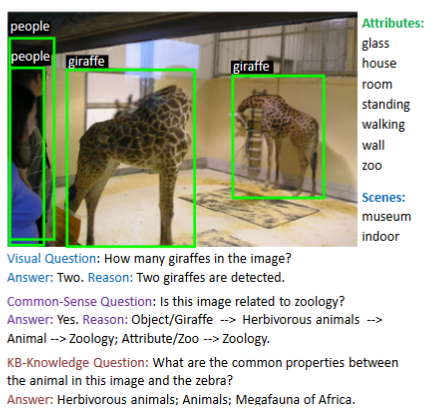
Size: 2190 images.
Paper
Web site
Created using: Images are taken from COCO and ImageNet datasets. Questions are synthesized by combining
the information associated with the images with knowledge is datasetss such as ConceptNet, DBpedia, and WebChild.
******************************************************
Description: Broadly speaking, an AI is shown a picture of a messy surface and has to figure out what is the right way to clean it up. More precisely: an instance consists of:
Example:

Size: Images of 70 surfaces with 308 objects.
Paper
Github
Created by:Images were provided by human participants.
******************************************************
Description: An instance consist of (a) an action; (b) multiple choice possible texts describing possible effects; (c) multiple choice images depicting possible effects.
Examples:
Action and effect text (correct answers)
| Action | Effect text |
|---|---|
| ignite paper | The paper is on fire. |
| soak shirt | The shirt is thoroughly wet. |
| stain shirt | There is a visible mark on the shirt. |
Positive images (top row) and negative images (bottom row) of the action,
peel orange.

Size: 140 actions. 1400 textual effects. 4163 images.
Paper
Web site
Created using: Crowd sourcing.
********************************************************
Description: PTR contains around 80k RGBD synthetic images with ground truth object and part level annotations regarding semantic instance segmentation, color attributes, spatial and geometric relationships, and certain physical properties such as stability. These images are paired with 800k machine-generated questions covering various types of reasoning types, making them a good testbed for visual reasoning models.
Examples:
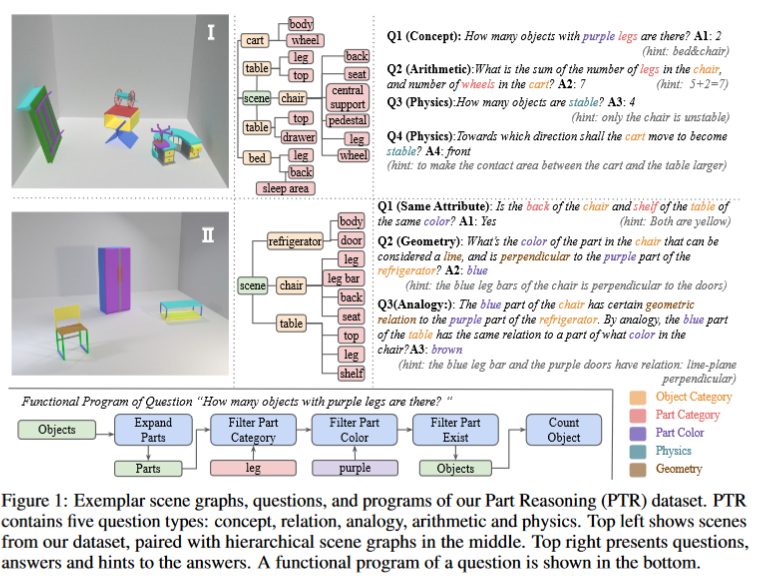
Size: 80k images, 800k questions
Paper
Web site
Created using: Both images and questions are synthetically generated.
******************************************************
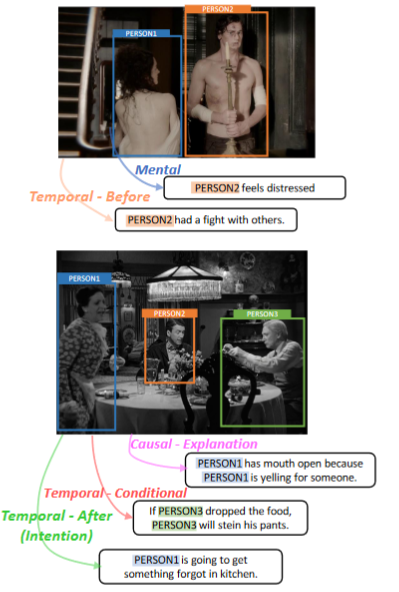
Description: The data set consists of images paired with abductive inferences that go beyond what is in the picture. There are three tasks: First, given an image, a region in the image, and a large collection of possible inferences, select the most plausible one supported by that region of the image. Second, given an image and an inference, find a region in the image that gives support to the inference. Third given an image, a region, and a small list of possible inferences, order the inferences by plausibility.
Example:
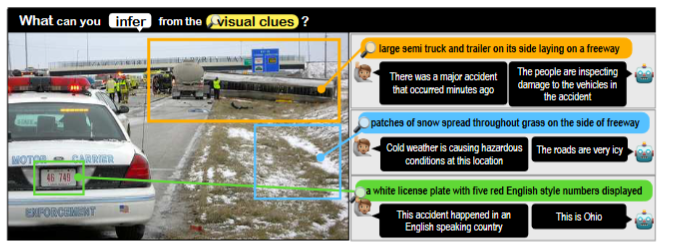
Size: 103,000 images, 363,000 inferences
Paper
Leaderboard
Created using: Crowd sourcing
*******************************************************
Description: Given an image and a question in natural language, give an answer and a justification (multiple choice).
Size: 290K multiple choice questions derived from 110K movie scenes.
Leaderboard.
Paper.
Created using: Crowd sourcing.
Examples:

*******************************************************
Description: Visual Genome is a large collection of richly annotated images. The images have an average of 35 objects, 26 attributes, 21 pairwise relations between objects, and 17 question/answer pairs. Each image is annotated in terms of a scene graph which enumerates the objects in the scene, and specifies the category of each object, its attributes, its spatial relation to other objects, and its bounding box in the image. Images are also annotated with significant regions in the image corresponding to closely interacting objects, and with question/answer pairs.
Visual Genome is more a resource than a benchmark and is more directed toward computer vision than toward commonsense reasoning as such. However, the question/answer pairs can certainly be used directly as a test set and the other forms of annotation somewhat more indirectly; and the associated technical paper discusses the importance of commonsense reasoning in doing these tasks.
The data set is notable for rich information, careful design, and the sheer amount of human labor that went into it, both from the scientists in design and from poorly-paid crowd workers in carrying out the annotations. "Overall, a total of over 33,000 unique workers contributed to the dataset. The dataset was collected over the course of 6 months after 15 months of experimentation and iteration on the data representation. Approximately 800, 000 Human Intelligence Tasks (HITs) were launched on AMT, where each HIT involved creating descriptions, questions and answers, or region graphs. Each HIT was designed such that workers manage to earn anywhere between $6-$8 per hour if they work continuously."
Example:
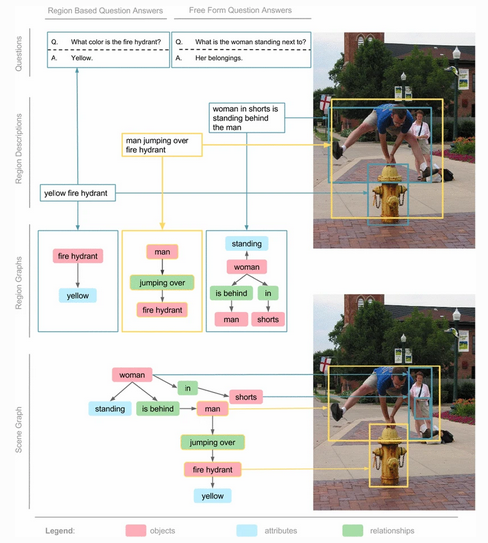
From
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
by Ranjay Krishna et al., Int. J. Computer Vision, 2017. Image published under a creative commons
licence.
Size: 108,000 annotated images.
Paper
Web site
Constructed using: Crowd sourcing
*******************************************************
Description: Each "riddle" consists in an image; a question, either open-ended, multiple-choice, or true-false, a hint, an attribution for the image, and the propt used to create the image.
Examples


Size: 400 riddles.
Created using: Images were created by text-to-image generation systems.
Textual elements were created by crowd workers.
Paper
Gotjib
*******************************************************
Description: A dataset of synthetic images that violate commonsense. There are four associated tasks: Generating explanations for why the image is anomalous, generating a caption, matching a detailed caption that indicates why the model is anomalous, and question answering.
Example:

Size: 500 images; 10,874 annotations.
Paper
Constructed using: Images created by image designers; text annotations
created by crowdworkers.
*******************************************************
Description: Given a textual cue and a collection of images, select the images that are related to the cue.
Size: 4482 examples with 5 or 6 candidate images; 1500 examples
with 10 or 12 candidate images.
Paper.
Github.
Created using: Gamification.
Example:
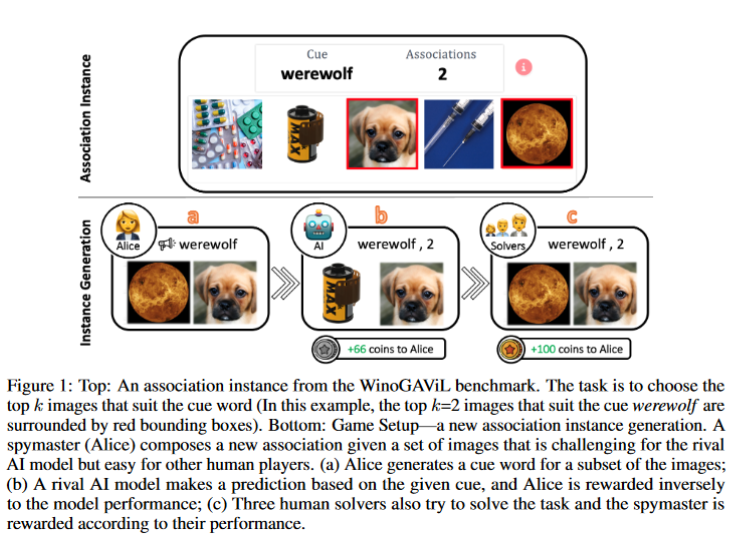
*******************************************************
Description: The goal is to use problems similar to the Winograd Schema Challenge to evaluate the commonsense abilities of a text-to-image generation system. The input is a prompt with an ambiguous pronoun. The output is an image illustrating the input. When the generation system reads the pronoun in the prompt, its attention in the image is tracked. We assume that the attention will be greater for the part of the images that displays what the system "believes" to be the referent of the pronoun. So if the attention for the pronoun more strongly overlaps the attention for the correct referent than for the incorrect reference, then that is considered a success.
Example:
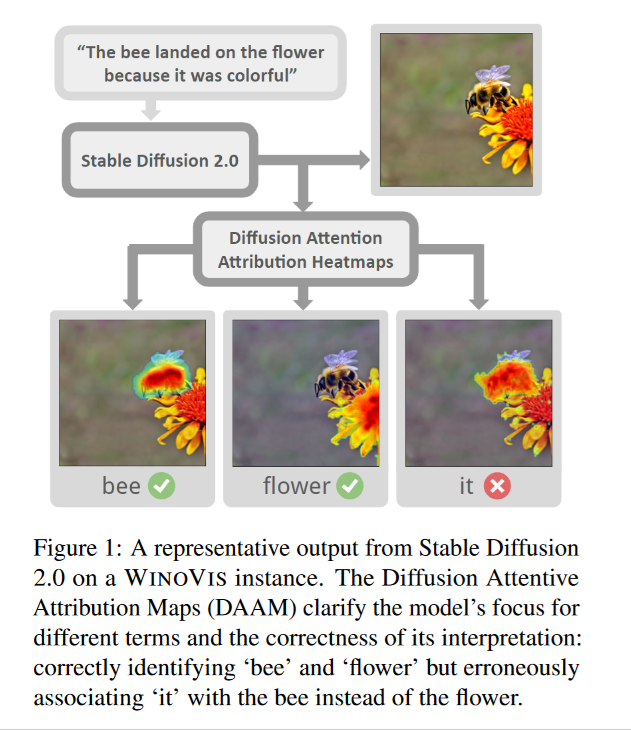
Size: 500 scenarios.
Paper
Github
Created using: Prompts created using GPT-4, and then filtered manually for suitability.