An ongoing, occasional series. Details are changed to protect confidentiality for unpublished papers. Published papers are fair game.
June 2024: If one is going to use Mikolov's famous theory of
vector arithmetic on word embeddings --- I don't particularly recommend
it, but there are worse things --- one should at least keep in mind that
it can only possibly apply to relations that are more or less single-valued
e.g.
\vec{London} — \vec{Britain} + \vec{France}= \vec{Paris}.
A paper
that I am reviewing proposes the equation
\vec{news} + \vec{about} = \vec{unemployment},
without realizing that the sum could just as plausibly be \vec{election},
\vec{war}, \vec{Ukraine}, \vec{Kate_Middleton} etc.
June 2024: Back in May, I was asked to review a paper submitted to a math journal. They claimed, among other things, that ChatGPT had "correctly provedn a quite tricky geometric inequality. They only included the first page of ChatGPT's proof, which was OK as far as it went. It seemed to me unlikely that ChatGPT could prove this, so I tried my own experiment with ChatGPT and, as I expected, it generated nonsense. E.g. the last step of the proof relied on the "inequality" 72*sqrt{3} > 5184. My review was unenthusiastic.
The authors resubmitted their paper a month later. This time they included
ChatGPT's entire proof with the comment both in their huffy response letter
and in their revised paper that, yes, ChatGPT has a random element and sometimes
produces flawed proofs, but that, for them, it had generated a valid proof.
It took me all of five minutes to determine that this other proof was also
nonsense. E.g. on the second page of output (out of 5) it cited the "identity"
a^6+b^6+c^6 = (a^2 + b^2+ c^2)(a^4 + b^4 + c^4 - (a^2b^2 + b^2c^2 +c^2a^2))
(Hint: Consider the case a=b=c=1.) I noted a couple of other errors, though
I saw no reason to waste my time working through the whole thing. Clearly
the authors
had not taken the 5 minutes needed to check this "proof". My review was still
negative, and I was annoyed, since it took me considerably more than 5
minutes to type it up in Latex
The day after I submitted my review, I got an email from the journal: "The authors submitted the wrong version. Please look over this new version." And lo and behold, this new version that they somehow failed to submit before, says that ChatGPT "pretends to have found a proof" of the statement and points out exactly the errors that I listed in my review.
I emailed the journal back that they must also have submitted the wrong version of their response letter, since the one they submitted defended the ChatGPT proof as correct, and that the authors had now gone from incompetence to dishonesty.
March 2024
In the current batch of papers reviewed for ACL ARR,
another paper conflated individuals with categories, with many references to
"fine-grained entities".
Another paper drew conclusions comparing performance of different AI's over
different categories from samples that ranged in size from 8 to 1. That
is, table 2 showed that on problems of category C, AI systems X and Y
scored 100% whereas system Z scored 0%. The discussion concluded that X and Y
were better than Z over problems of category C. Table 1 shows that their sample
for category C had a single instance.
February 2024
I'm reviewing a paper which reanalyzes the Ptolemaic, Copernican, and
Keplerian theories of planetary motion, and their fit to observational
data, as a historical study in the progress of science, which they claim
has cognitive implications. The problem is that they get the Copernican
theory wrong. Their idea of the Copernican model is that it has the
planets circling the sun on circular orbits at constant angular velocity.
Based on that assumption, they determined that that theory actually
fits the data worse than the Ptolemaic, and they build up a whole
meta-theory of how science chooses between theories on that assumption.
As a glance at Wikipedia or any other history of science would have told
them, Copernicus theory, like the Ptolemaic theory, had epicycles for
each of the planets and was thus able to achieve a better fit to the data.
They also simplify the whole thing, by assuming that all planetary orbits are co-planar, and they of course ignore the serious (at the time) arguments against the heliocentric theory, such as the absence of parallax for the fixed stars, which was not fully answered until the mid-18th century, but those are comparatively minor issues.
December 2021
A
new paper on arXiv claims "We solve MIT’s Linear Algebra 18.06 course and Columbia University’s Computational Linear Algebra COMS3251 courses with perfect accuracy by interactive program synthesis." "Our results open the door for solving other STEM courses, which has the potential to disrupt higher education by: (i) automatically learning all university level STEM courses, (ii) automatically grading course, and (iii) rapidly generating new course content."
In fact, of the 60 examples of textbook problems listed in the appendix, 8 are simply wrong, and in 6 most of the work is being done by the human in the loop rather than by Codex. Plus, the only problems considered are those involving computing this or that rather than questions that ask you to explain or prove something. Some of the successes are actually impressive, but most are just pattern-matching phrases in the prompt with calls to functions in NumPy.
November 2021
I'm reviewing a journal paper by PhD student, PhD student, PhD student, and adviser at a fine university. It contains a dozen or so formulas like
P(x) = ∃ Q(x) ^ W(x,y) ∀ (y ∈ S).and similar horrors for set construction and for summation over a set. There are no well-formed formulas that use a quantifier or min/max anywhere in the paper.
a = x | max(f(x,y) ∀ y ∈ S)
This is not actually the most important thing that's bad about the paper -- what's most importantly bad is that it is addressing a useless problem using a method that does not generalize past a very specific toy microworld --- but that kind of flaw is excusable. This pure incompetence is not.
Maybe this is just a "grass is greener" viewpoint, but it's not my impression that doctoral students in physics, chemistry, math, economics or other areas of computer science submit papers with simple formulas that are obviously ill-formed. My impression is that it's unique to symbolic AI. Incidentally, the adviser certainly knows better; they just didn't bother reading the paper.
I don't make great claims for my abilities as a pedagogue, but at least the students in my AI classes (undergrad and graduate) come out aware that, if they write a formula like the first one above, they will be executed by firing squad at dawn. (I don't specifically teach the correct form for "max".)
November 2021
I am reviewing a grant proposal. The PI reproduces a figure from one
of their papers with no explanation in the text. I can make sense of
neither the label on the x-axis, the label on the y-axis, or the various
acronyms that label the six curves shown. I do see clearly, though,
that something goes down as a function of something else, along six
different possible paths depending on some other thing, with confidence
intervals that are pretty broad but do not wipe out the trend. I
presume that that's a good thing. Unfortunately I obviously can't post.
September 2021
Reviewer 2 is reviewing a paper by a fine scientist and their student.
It is both technically incompetent and poorly written. He presumes that
the scientist didn't even bother to look at it. He spent a
couple of hours of his not entirely valueless time going through it and
writing up a 1000 word review explaining what's wrong with the thing.
He feels that he and the other reviewers are being asked to do, as
reviewers, work that the scientist should have done as an advisor.
June 2021
Automated commonsense reasoning in 2021:
< rant > I'm reviewing a paper on the topic of "Commonsense Q/A". They explain at length how their system can answer the following question that they claim is from the WIQA dataset (I haven't checked): "Suppose during boiling point happens, how will it affect more evaporation?" (Possible answers: "more", "less" or "no effect".) This is the example they chose; I didn't cherry pick it.
The new technique that they're using (combined with random BERT-based slop) is exactly the spreading activation model proposed by Ross Quillian (1968). Needless to say they don't cite Quillian. (Incidentally, they have 30 lines of pseudo-code explaining bidirectional breadth-first search, because readers who know every detail of BERT, RoBERTa and so on have never heard of it.) The network is, God help us, ConceptNet. Or rather, like at least two other papers I've reviewed in the last year, it's a stripped down version of ConceptNet, which entirely ignores the labels on the arrows because, of course, binary relations are much too hard to reason about.
It's nonsense piled on garbage tested on gibberish.
But of course it has its bold-faced results table showing that, on this challenging, well-established dataset and some others (on which MTurkers achieved 96%!) it outshines all the previous systems. _And_ an ablation study. How could I possibly justify denying it its day in the sun? < /rant >
It's possible, certainly, that the point about the arcs in ConceptNet cuts the other way: that the labels on the arcs are so vague and ad hoc that they are, in fact, useless; the only value of ConceptNet is in the nodes and the unlabelled arcs.
February 2021
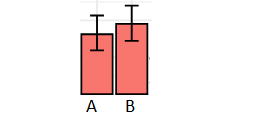
Figure in a paper I'm reviewing, with the caption,
"Since B is bigger than A, we can conclude ..."
October 2020
I'm reviewing a grant proposal for a good-sized amount of money, which
(parts I-V.D) wants to do theoretical math in logic and topology, and
(part V.E) will use all this math in order to do medical image analysis
on pictures of tumors. They mention that the techniques they've
developed have already achieved state-of-the-art on some class of
images. So I looked up the paper about the tumors. Sections 1-7 are
theoretical math. Section 8 gives a program listing with 8 lines of
code for characterizing tumors (not including the subroutines, but
those seem pretty basic). The code, of course, has absolutely
nothing to do with the math, plus it's the kind of image processing
that people were doing 40 years ago. It's the kind of code that a
mathematician who has grudgingly spent a couple of hours reading some
basic papers about medical images might write.
So I'm writing a review that says (a) the math looks cool (b) the medical imaging is completely bogus. If the funding agency wants to spend a lot of money on logic and topology, more power to them, but nobody should be pretending that this is going to help in hospitals.
September 2005
Mathematics as Metaphor.
A review of Where Mathematics Comes From, by George Lakoff and
Raphael Nunez. Journal of Experimental and Theoretical AI,
vol. 17, no. 3, 2005, pp. 305-315.
Back in the early 1990s
The absolute worst paper I ever reviewed, back when non-monotonic logic
and "the software crisis" were both hot, was entitled something like
"The software crisis and nonmonotonic logic" and, without exaggeration,
ran as follows: