 |
- Time Period: 2008 - present.
- Participants: Karol Gregor, Koray Kavukcuoglu, Arthur Szlam, Rob Fergus, Yann LeCun (Courant Institute/CBLL).
- Sponsors: ONR, NSF.
- Description: We are developing unsupervised (and semi-supervised) learning algorithms to learn
visual features. The methods are based on the idea that good feature representation should be high dimensional
(so as to facilitate the separability of the categories), should contain enough information to reconstruct the
input near regions of high data density, and should not contain enough information to reconstruct inputs in
regions of low data density. This lead us to use sparsity criteria on the feature vectors. Many of the sparse coding
methods we have developed include a feed-forward predictor (a so-called encoder) that can quickly produce an
approximation of the optimal sparse representation of the input. This allows us to use the learned feature
extractor in real-time object recognition systems. Variant of sparse coding are proposed, including one
that uses group sparsity to produce locally invariant features, two methods that separate the "what" from
the "where" using temporal constancy criteria, and two methods for convolutional sparse coding, where the
dictionary elements are convolution kernels applied to images.

Examples of filters learned from natural image patches using the Predictive Sparse Decomposition algorithm (PSD).
The objective of sparse coding is to reconstruct an input
vector (e.g. an image patch) as a linear combination of
a small number of vectors picked from a large dictionnary.
This is common known as basis pursuit.
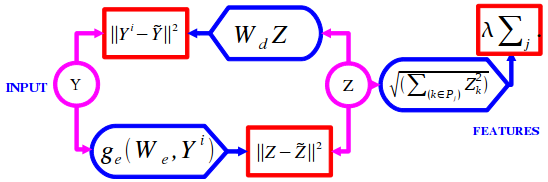
In the most common form, the feature vector Z that represents an input
vector Y (the optimal code for Y), is the one that minimizes the
following L2-L1 energy function:
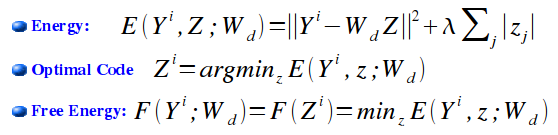
The process can be described by a factor graph:
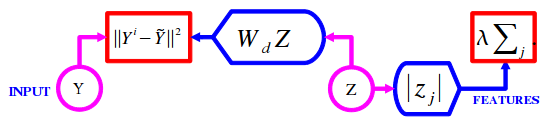
where red rectangles represent factors, circles represent
variables, and blue modules represent deterministic functional
relationships.
As shown by Olshausen and Field in 1997, the basis functions can be
learned by minimizing the free energy, averaged over a training set of
input samples with respect to the dictionary matrix Wd whose columns
are the dictionary elements. The norm of the dictionary elements is
constrained to be less than 1. The minimization can be performed
through stochastic gradient descent.
| Predictive Sparse Decomposition (PSD) |
One problem with traditional sparse coding is that inference is
somewhat slow. Give an input vector, finding the corresponding code
vector requires an L2/L1 optimization. Having to do this for every
patch in an image would preclude the use of sparse coding for
high-speed image recognition.
Predictive Sparse Decomposition (PSD) alleviates this problem by
training a simple, feed-forward encoder module to predict an
approximation to the optimal sparse code. The factor graph is shown
below.
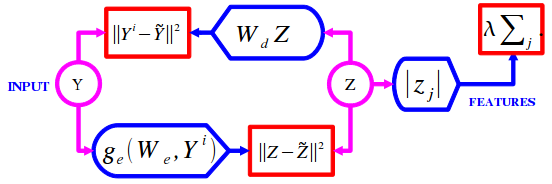
This could be seen as a kind of auto-encoder. The energy
function has an additional term, which measure the discrepancy
between the predicted code and actual code. The encoder can take
several function forms. In the simplest instance, it is simply
a linear transform, followed by a sigmoid non-linearity, and
a trainable diagonal gain matrix.

The animation below shows the filters being learned by the PSD
learning procedure, when trained on 12x12 pixel patches from
natural images.

| Learned Iterative Shrinkage and Thresholding Algorithm (LISTA) |
The simple encoder described above generally doesn't predict sparse
codes. In this work (published at ICML 2010), we propose to build the
encoder architecture so as to follow that of the so-called ISTA or
FISTA algorithm (Fast Iterative Shrinkage and Thresholding Algorithm),
which has been shown to converge to the optimal sparse code
solution. We build the encoder as a feed forward network with the same
architecture as an time-unrollled version version of the ISTA/FISTA
algorithm (trucated to a few iterations). The block diagram of
ISTA/FISTA and the corresponding encoder is shown below. With ISTA and
FISTA, the two matrices We and S have prescribed values. We is the
transpose of the dicionary matrix, and S is the identity minus some
constant times the gram matrix of the dictionary elements. In our method,
called LISTA (Learned ISTA), the matrices are trained so as to produce
the best approximation of the optimal sparse code with the given
number of iterations.
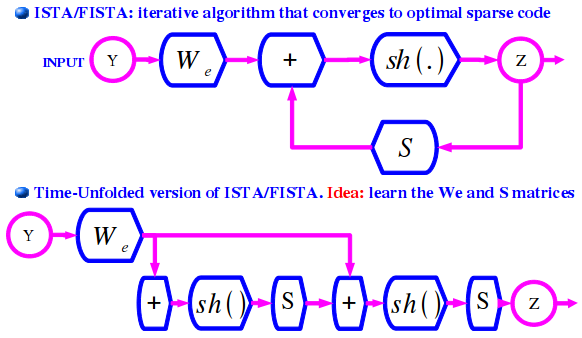
The approximations are shown experimentally to be considerably better
than simply truncating the FISTA algorithm to the same number of
iterations. A learned version of the Coordinate Descent algorithm
(which is faster than FISTA) is also presented.
A problem with sparse coding, when applied to images, is that it is
trained on individual patches, yet it is often used convolutionally
(applied to sliding windows over the whole image). Because the
training is done on indivudual patches, the dictionary elements must
cover the entire patch. Hence we the same Gabor filter replicated and
multiple shifted locations over the patch. This is very wasteful when
features are to be extracted over entire images using a sliding window
approach: the code ends up being extremely redundant.
Convolutional Sparse Coding consists in viewing the dictionary
elements as convolution kernels applied to a large image region,
as shown in the diagram below

With this method, the dictionary elements are considerably
less redundant. Since there are shifted versions of each
dictionary element because of the convolution operation, the
algorithm doesn't need to learn multiple shifted replicas
of each filter to cover the patches. This results in considerably
more diverse filters, such as center-surround, cross and corner
detectors, Gabors at multiple frequencies, etc....

Our colleagues Zeiler, Taylor, Krishnan, and Fergus described
such a method, called deconvolutional networks in a
CVPR 2010 publication. Our method is a convolutional version
of PSD, which includes a fast encoder. The fast encoder uses
the soft-shrinkage function as its non-linearity.
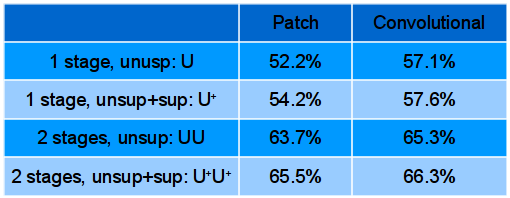
Sparse features learned with Convolutional PSD yield much better results
on Caltech-101 than sparse features learned with conventional
sparse coding (or PSD) trained at the patch level:
| Convolutional Matching Pursuit |
Matching Pursuit is a "greedy" form of sparse coding.
We have proposed a convolutional form of Matching Pursuit
that produces extremely parsimonious representations
of images.
The picture below (left) shows examples of filters learned with
Convolutional MP. On the right, we see an image of a face
(pre-processed with high-pass filtering and contrast normalization),
together with its reconstruction with Convolutional MP using only 40
non-zero coefficients.

| Learning Invariant Features with Group Sparsity |
Group sparsity consists in grouping components of the sparse code into
groups. The sparsity criterion applies to groups. It tends to minimize
the number of groups that contain non-zero code components, but if one
group is active, it doesn't restrict the number of non-zero components
within the group. This is acheived using an L2 norm of the code components
in each group as the sparsity criterion.
During learning, the group sparsity criterion tends to produce filters
within a group that fire together. Hence, filters within a group tend
to be very similar (e.g. Gabor edges at similar orientations).
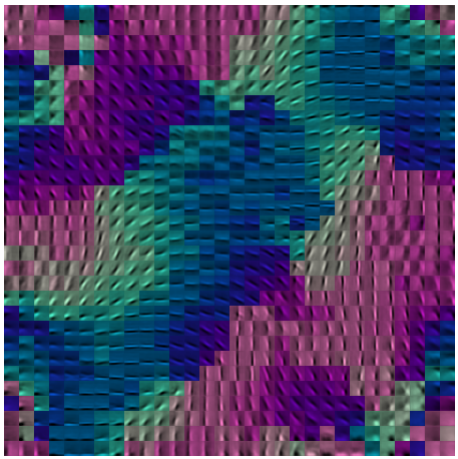
In the chart below, the code components were arranged in a 2D toroidal
topology, and the groups were overlaping sqquares (as shown). The
filters arrange themselves in a smoothly-varying topographic map.

| Learning Locally-Connected Filters with Group Sparsity |
Sparse coding was originally proposed as a model of simple cells in
the visual cortex. In the present project, the filters are arranged
over an input image. EAch filter has a local receptive field on the
image. A layer of complex-cell-like pooling combines the outputs of
local groups of units. A sparsity criterion is applied to these
groups. The result is a topographic map with pinwheel patterns
similar to those observed in the visual cortex.

| arXiv |
Arthur Szlam, Koray Kavukcuoglu, Yann LeCun:
Convolutional Matching Pursuit and Dictionary Training, October 2010.
| arXiv:1010.0422 |
| arXiv |
Karol Gregor, Yann LeCun:
Emergence of Complex-Like Cells in a Temporal Product Network with Local Receptive Fields, June 2010.
| arXiv:1006.0448 |
| 148. |
Karol Gregor and Yann LeCun: Learning Fast Approximations of Sparse Coding, Proc. International Conference on Machine learning (ICML'10), 2010, \cite{gregor-icml-10}.
|
178KB | DjVu |
| 226KB | PDF |
| 255KB | PS.GZ |
| 146. |
Y-Lan Boureau, Francis Bach, Yann LeCun and Jean Ponce: Learning Mid-Level Features for Recognition, Proc. International Conference on Computer Vision and Pattern Recognition (CVPR'10), IEEE, 2010, \cite{boureau-cvpr-10}.
|
178KB | DjVu |
| 225KB | PDF |
| 229KB | PS.GZ |
| 144. |
Yann LeCun, Koray Kavukvuoglu and Clément Farabet: Convolutional Networks and Applications in Vision, Proc. International Symposium on Circuits and Systems (ISCAS'10), IEEE, 2010, \cite{lecun-iscas-10}.
|
189KB | DjVu |
| 266KB | PDF |
| 339KB | PS.GZ |
| 140. |
Kevin Jarrett, Koray Kavukcuoglu, Marc'Aurelio Ranzato and Yann LeCun: What is the Best Multi-Stage Architecture for Object Recognition?, Proc. International Conference on Computer Vision (ICCV'09), IEEE, 2009, \cite{jarrett-iccv-09}.
|
303KB | DjVu |
| 769KB | PDF |
| 834KB | PS.GZ |
| 137. |
Koray Kavukcuoglu, Marc'Aurelio Ranzato, Rob Fergus and Yann LeCun: Learning Invariant Features through Topographic Filter Maps, Proc. International Conference on Computer Vision and Pattern Recognition (CVPR'09), IEEE, 2009, \cite{koray-cvpr-09}.
|
334KB | DjVu |
| 864KB | PDF |
| 1474KB | PS.GZ |
| 9. |
Koray Kavukcuoglu, Marc'Aurelio Ranzato and Yann LeCun: Fast Inference in Sparse Coding Algorithms with Applications to Object Recognition, Computational and Biological Learning Lab, Courant Institute, NYU, Tech Report CBLL-TR-2008-12-01, 2008, \cite{koray-psd-08}.
|
99KB | DjVu |
| 343KB | PDF |
| 384KB | PS.GZ |
| 128. |
Marc'Aurelio Ranzato, Y-Lan Boureau and Yann LeCun: Sparse feature learning for deep belief networks, Advances in Neural Information Processing Systems (NIPS 2007), 2007, \cite{ranzato-nips-07}.
|
129KB | DjVu |
| 174KB | PDF |
| 212KB | PS.GZ |
| 127. |
Marc'Aurelio Ranzato and Yann LeCun: A Sparse and Locally Shift Invariant Feature Extractor Applied to Document Images, Proc. International Conference on Document Analysis and Recognition (ICDAR), 2007, \cite{ranzato-icdar-07}.
|
139KB | DjVu |
| 205KB | PDF |
| 228KB | PS.GZ |
| 125. |
Yann LeCun, Sumit Chopra, Marc'Aurelio Ranzato and Fu-Jie Huang: Energy-Based Models in Document Recognition and Computer Vision, Proc. International Conference on Document Analysis and Recognition (ICDAR), (keynote address), 2007, \cite{lecun-icdar-keynote-07}.
|
110KB | DjVu |
| 355KB | PDF |
| 551KB | PS.GZ |
| 119. |
Marc'Aurelio Ranzato, Fu-Jie Huang, Y-Lan Boureau and Yann LeCun: Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition, Proc. Computer Vision and Pattern Recognition Conference (CVPR'07), IEEE Press, 2007, \cite{ranzato-cvpr-07}.
|
187KB | DjVu |
| 331KB | PDF |
| 343KB | PS.GZ |
| 118. |
Marc'Aurelio Ranzato, Y-Lan Boureau, Sumit Chopra and Yann LeCun: A Unified Energy-Based Framework for Unsupervised Learning, Proc. Conference on AI and Statistics (AI-Stats), 2007, \cite{ranzato-unsup-07}.
|
257KB | DjVu |
| 240KB | PDF |
| 320KB | PS.GZ |
| 115. |
Marc'Aurelio Ranzato, Christopher Poultney, Sumit Chopra and Yann LeCun: Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2006, \cite{ranzato-06}.
|
152KB | DjVu |
| 191KB | PDF |
| 204KB | PS.GZ |
|
|