FinTime --- a financial time series benchmark
Kaippallimalil J. Jacob
Morgan Stanley Dean Witter & Co., New York (kjacob@acm.org)
&
Dennis Shasha
Prof, Computer Science Dept, Department of
Computer Science
Courant Institute of
Mathematical Sciences
New York University
Dennis Shasha's home page
(shasha@cs.nyu.edu)
FinTime home page
Abstract
Time-series databases are of critical
importance to finance and related applications. Many database vendors have
made rapid progress in the implementation of these systems with increasing
powerful capabilities and greater performance. Faced with a number of systems
that claim support for time-series data it is quite difficult for a user to
make an informed decision. Consequently, there is a need for a benchmark that
characterizes these systems. The FinTime benchmark tries to model the practical
uses of time-series databases in financial applications. FinTime will evolve
with the help of vendors and customers.
.
Introduction
This document presents the models
underlying the benchmark and suggests a few metrics to capture the performance
of the systems. The models suggested in FinTime reflect two frequently
occurring cases in the financial industry, namely, a historical market data
system and real-time price tick database. These models are quite similar to two
well-studied models in the relational world, respectively,
decision support systems
and OLTP systems. FinTime also suggests and defines metrics that capture three
useful dimensions of any time-series system, namely, performance in a
single-user mode, performance in a multi-user mode and the price to performance
ratio.
Models for a Time-series Benchmark
Before deciding on a model, we have to
examine the different parameters that determine a model for time-series system.
The most important parameters that influence a time-series database system
are:
- Periodicity of data (Regular/irregular)
- Density of data (Dense/Sparse)
- Schedule of updates (periodic, continuous)
- Types of queries (Simple/Complex)
- Time interval between queries (Ad hoc/Batch)
- Number of concurrent users (Few/Many)
Combinations of these factors will give rise to 64 possible models but for
simplicity we can focus on the following commonly occurring cases in the
financial industry
Model 1: Historical market Information
|
Attribute |
Specification |
|
Periodicity of Data |
Periodic |
|
Density of Data |
Dense |
|
Schedule of updates |
Periodic updates (e.g. at the end of a business
day) |
|
Complexity of queries |
Complex (e.g. Decision support queries) |
|
Nature of query arrival |
Batch |
|
Concurrency of users |
Low (e.g. Few concurrent users) |
Model 2: Tick databases for financial instruments
|
Attribute |
Specification |
|
Periodicity of Data |
Non-periodic |
|
Density of Data |
Sparse to moderately dense |
|
Schedule of updates |
Continuous |
|
Complexity of queries |
Simple |
|
Nature of query arrival |
Ad hoc |
|
Concurrency of users |
High (e.g. Many concurrent users) |
Let us now discuss the characteristics of the two models in some detail
(Datatypes used in the models are explained in greater details in the
glossary)
Model 1: Historical Market Information
Historical Market data systems are closely related to decision
support systems of the traditional relational database world. The various
elements of this model are:
- Data Model:
In the case of historical time-series databases for
market information, the model consists of a few relational tables that
typically contain infrequently changing (static) information and a number of
time-series tables. The following tables describe the data in this
benchmark
Base Information Table
|
Field Name |
Type |
Comments |
|
Id |
Char(30) |
Unique Identifier for the financial instrument e.g.
IBM.N |
|
Ex |
Char(3) |
Exchange on which the instrument is traded e.g. "N" for
the New York Stock Exchange |
|
Descr |
Varchar(256) |
A brief description of the financial security e.g.
"International Business Machines, Armonk, NY" |
|
SIC |
Char(10) |
Standard Industry Code e.g. "COMPUTERS" or
"CHEMICAL" |
|
SPR |
Char (4) |
S&P Rating for the company e.g. "AAA" |
|
Cu |
Char(5) |
The base currency in which the security is traded e.g.
"USD" for US Dollars |
|
CreateDate |
Date |
Date this security came into existence |
Stock Splits (Irregular Time-series)
|
Field Name |
Type |
Comments |
|
Id |
Char(30) |
Identifier |
|
SplitDate |
Date |
Date the split is actually effective |
|
EntryDate |
Date |
Date the split is announced |
|
SplitFactor |
Double |
The split factor expressed as a decimal value. E.g. a 2
for 1 split is expressed as 0.5 (ie 1/2), a 4 for 3 is expressed as 0.75(ie
3/4) |
Dividends (Irregular Timeseries)
|
FieldName |
Type |
Comments |
|
Id |
Char(30) |
Identifier |
|
XdivDate |
Date |
Date on which dividend is disbursed |
|
DivAmt |
Double |
Dividend Amount In the base currency of the
instrument |
|
AnnounceDate |
Date |
Date on which the dividend is announced |
Market Data (Regular Timeseries)
|
FieldName |
Type |
Comments |
|
Id |
Char(30) |
Identifier |
|
Tradedate |
Date |
Trade Date |
|
HightPrice |
Double |
High price for the day |
|
LowPrice |
Double |
Low price for the day |
|
ClosePrice |
Double |
Closing price for the day |
|
OpenPrice |
Double |
Open price for the day |
|
Volume |
Long |
Volume of shares traded |
- Data population, volume of data and update mechanism
. Having defined
the data model let us discuss the manner in which the data is fed to the
database. Market information is typically provided as a set of input files by a
market data vendor at the end of each trading day. These files
correspond to the tables defined above. While the data for the Base
Information table, Split Adjustment Table and Dividend
Table is irregular (i.e. an external event triggers an entry into these
tables), the Market Information Table has an entry for every trading
day. For the purposes of this benchmark the implementation can select a scale
factor combination of the number securities under consideration and the number
of events for those securities. We suggest 3 scale factors, namely, 50,000
securities, 100,000 securities, and 1,000,000 securities, all for 4,000 days.
These roughly correspond to all equity securities in the US, all equity
securities in the G7 countries and all equity securities in the world. Programs
to generate the data can be found
here .
- Query characteristics
. Having defined the data model and the data
generation mechanisms, let us now focus on the queries that are executed
against the database. The characteristics of the database system that is being
tested by the queries are as follows:
- Join of relational data and time-series information
- Access of long depth time-series information for a few keys (deep history
query)
- Access of a short depth time-series for a large number of keys
(cross-sectional queries)
- Sorting
- Grouping and Aggregation
Following are the benchmark queries to be run against the data model defined
above. Many of them include a notion of ``specified set of securities'' or
``specified period''. This notion is defined in the glossary with respect to a
simple random model.
|
1 |
Get the closing price of a set of 10 stocks for a 10-year
period and group into weekly, monthly and yearly aggregates. For each aggregate
period determine the low, high and average closing price value. The output
should be sorted by id and trade date. |
|
2 |
Adjust all prices and volumes (prices are multiplied by
the split factor and volumes are divided by the split factor) for a set of 1000
stocks to reflect the split events during a specified 300 day period, assuming
that events occur before the first trade of the split date. These are called
split-adjusted prices and volumes. |
|
3 |
For each stock in a specified list of 1000 stocks, find
the differences between the daily high and daily low on the day of each split
event during a specified period. |
|
4 |
Calculate the value of the S&P500 and Russell 2000
index for a specified day using unadjusted prices and the index composition of
the 2 indexes (see appendix for spec) on the specified day |
|
5 |
Find the 21-day and 5-day moving average price for a
specified list of 1000 stocks during a 6-month period. (Use split adjusted
prices) |
|
6 |
(Based on the previous query) Find the points (specific
days) when the 5-month moving average intersects the 21-day moving average for
these stocks. The output is to be sorted by id and date. |
|
7 |
Determine the value of $100,000 now if 1 year ago it was
invested equally in 10 specified stocks (i.e. allocation for each stock is
$10,000). The trading strategy is: When the 20-day moving average crosses over
the 5-month moving average the complete allocation for that stock is invested
and when the 20-day moving average crosses below the 5-month moving average the
entire position is sold. The trades happen on the closing price of the trading
day. |
|
8 |
Find the pair-wise coefficients of correlation in a set
of 10 securities for a 2 year period. Sort the securities by the coefficient of
correlation, indicating the pair of securities corresponding to that row.
[Note: coefficient of correlation defined in appendix] |
|
9 |
Determine the yearly dividends and annual yield
(dividends/average closing price) for the past 3 years for all the stocks in
the Russell 2000 index that did not split during that period. Use unadjusted
prices since there were no splits to adjust for. |
Since the benchmark model assumes that the level of concurrency is
small, the number of users should be 5. The benchmark methodology should be
that each of the five users executes all the queries listed above in a randomly
generated permutation. The five users will be simultaneously active at any
point in time. Where the output order is not specified, it can be
displayed/stored in any order.
Model 2: Tick databases for financial instruments
This benchmark models a very different, but commonly occurring,
scenario from the one above. In this case, the benchmark attempts to model a
case where the database is expected to keep up with a very high rate of updates
while responding to several users issuing fairly simple queries. This case is
quite similar to OLTP systems in the relational world.
The case being modeled is the tick database for a financial system. Ticks
are price quotation or trade (transaction) prices and associated attributes for
individual securities that occur either on the floor of a stock exchange or in
an electronic trading system, such as the NASDAQ market system. Ticks include 2
basic kinds of data (1) Trades are transactions between buyers and a sellers at
a fixed price and quantity (2) Quotes are price quotations offered by buyers
and sellers. Quotes can have the ask quote, the bid quote or both along with
their associate attributes such as quantity offered.
Let us now define the different elements of this benchmark. They are:
- Data model.
The data model for this benchmark is simple. It consists
of the following 2 tables:
Base Information Table
|
Field Name |
Type |
Comments |
|
Id |
Char(30) |
Identifier for a security |
|
Ex |
Char(3) |
Exchange on which the instrument is traded e.g. "N" for
the New York Stock Exchange |
|
Descr |
Varchar (256) |
A short description of the security |
|
SIC |
Char(10) |
The standard industry code for the security |
|
Cu |
Char(10) |
Base currency for the security |
Trades/Quotes Table
|
FieldName |
Type |
Comments |
|
Id |
Char(30) |
Identifier |
|
SeqNo |
Long |
A unique sequence number for each trade or
quote |
|
TradeDate |
Date |
The trading date |
|
TimeStamp |
Time |
The time a particular trade was executed or Quote was
generated |
|
TradePrice |
Double |
The price at which the trade was executed |
|
TradeSize |
Long |
The number of shares traded in a transaction |
|
AskPrice |
Double |
The Price at which a seller would sell a
security |
|
AskSize |
Double |
The size of the transaction offered at the specified ask
price. |
|
BidPrice |
Double |
The price at which a buyer would buy the security
|
|
BidSize |
Double |
The size of the transaction offered at the specified bid
price |
|
Type |
Char |
An indication if this is a quote or a trade |
- Data population, Update frequency and volume.
Tick databases are
generally populated by adapters that receive data from real-time feeds. The
frequency of updates is constantly increasing but on the average we can assume
that each security ticks (each corresponding to a record in the database) about
100 times during an 8-hour trading day. Additionally, we can assume that the
set of securities being tracked is traded around the world and hence there is
no quiescent period. For the purposes of this benchmark we will assume that the
system monitors ticks on 1,000, 10,000 or 100,000 securities, where each
represents a different scale factor.
A very important consideration in tick databases is the ability to quickly
apply "cancel/correct". Occasionally an incorrect quote or trade record is
published. The vendor will then send a correction record with the identifier of
the security and its sequence number. The record will either be corrected
according to the newly published data or simply deleted.
- Query characteristics. The kinds of queries issued against an online tick
databases are usually simple and pre-determined. Listed below are the set of
queries to be used in the benchmark.
- Updates Between Queries (new, June 6, 1999):
After each query, 200 rows from the
Trades/Quotes table are chosen randomly and uniformly and each price
field is changed to a value chosen randomly and uniformly between
0 and twice its current price.
|
1 |
Get all ticks for a specified set of 100 securities for a
specified three hour time period on a specified trade date. |
|
2. |
Determine the volume weighted price of a security
considering only the ticks in a specified three hour interval |
|
3. |
Determine the top 10 percentage losers for the specified
date on the specified exchanges sorted by percentage loss. The loss is
calculated as a percentage of the last trade price of the previous
day. |
|
4. |
Determine the top 10 most active stocks for a specified
date sorted by cumulative trade volume by considering all trades |
|
5. |
Find the most active stocks in the "COMPUTER" industry
(use SIC code) |
|
6. |
Find the 10 stocks with the highest percentage spreads.
Spread is the difference between the last ask-price and the last bid-price.
Percentage spread is calculated as a percentage of the mid-point price (average
of ask and bid price). |
- Operational parameters.
Since usually tick systems have a relatively
large number of concurrent users, we will assume that there are 50 concurrent
users for the benchmark. These users will execute all of the queries listed
above in a random permutation. Each user will submit each query only once and
run through the complete list of queries. Where not specified the output order
is not significant.
Metrics
Here are metrics to allow customers to
compare one set of results against another. Each metric should be stated with
respect to a scale factor and results for Historical Market Information should
be reported separately from results for Tick Databases. For Historical Market
Information, the scale factor is the number of securities, assuming 4,000 days
of history. For Tick Databases, the scale factor is also the number of
securities, assuming 100 ticks per security per day and 90 days of history.
Since the queries entail random selections from larger sets as explained in the
glossary (e.g. ``specified set of 100 securities''), these tests should be run
10 times and vendors should report averages and standard deviations.
- Response Time Metric
: A single user metric
This can be defined as the geometric mean of the execution time of each of
the queries executed one after the other in a single-user mode
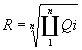 Where Qi is the Execution time
for query i
Where Qi is the Execution time
for query i
- Throughput Metric
: A multi-user metric
The Throughput Metric is defined as the average time taken by a user to
complete his workload in a multi-user system.
Thus if Ei = total elapsed time for user "i" to execute the set of queries,
then the throughput measure is define as
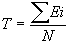 Where Ei
= elapsed time to execute the set of queries for user i
Where Ei
= elapsed time to execute the set of queries for user i
Cost Metric. A cost measure
The cost metric is used to bring the capabilities of the hardware into the
equation. It is based on the assumption that additional hardware capabilities
would be reflected in higher hardware costs. Thus the cost metric is defined
as
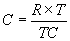
where R = Response metric
T = Throughput metric
TC = Total cost of the system in $
Constraints
Full ACID property for transactions. This
constraint is applicable to both models, where updates are applied concurrently
with queries.
For either benchmark, each user must execute the complete query set once.
They do not have the option of selecting a subset of queries or re-executing a
query.
Conclusions
Benchmarks help compare different products
that solve the same problem. It gives the potential user of these systems a
meaningful way of assessing the capabilities of differing products. Since it is
quite difficult to capture all the information about a system in a few
benchmark measures, it is important that the implementation of this benchmark
record the exact conditions under which the tests were carried out and the
results that were used to arrive at the metrics. Eventually, these conditions
will fall under a certification procedure.
Bibliography
Transaction Processing
Council (1998
), "TPC-D Benchmark Specification" Version 2.0.
M. Stonebraker (1998), "Performance and Database Machines", Readings in
Database Systems, Morgan-Kaufmann, San Mateo
D. Biiton, D. De Witt and C. Turbyfill (1983), "Benchmarking Database
Systems: a systematic approach", Proceedings of the Ninth Very Large
Database Conference, Florence, Italy
M. J. Carey, D. J. deWitt and J. F. Naughton (1993), "The OO7
Benchmark", Proceedings of the ACM SIGMOD International Conference on
Management of Data, Washington D.C.
A. B. Chaudhri (1996), "An Annotated Bibliography of Benchmarks for
Object Databases",
Glossary
Defined below are some concepts and
measures commonly used in the financial industry and referred to in the
benchmark specification
- Split and Reverse Splits: A stock split is a process in which one share of
a security is converted into a specified number of shares. A reverse split is
the opposite process where a number of shares of a security is converted into 1
share. The ratio between the number of old securities and the new ones is
called the split factor. E.g. If a security splits "2 for 1" the split factor
is 0.5. If a security reverse splits "1 for 3" the split factor is 3/1 or
3.
- Adjusted prices and volume. Since splits and reverse splits change the
value of a security at the point the event occurs. E.g. Assume that an order to
purchase 100 shares of a security at $50 per share was placed before a split.
After a "2 for 1" split is effected, the order will be for 200 shares at $25.
Notice that the total value of the order has not changes. However the price was
multiplied by the split factor and the volume was divided it. A more
comprehensive example follows. Consider the following snapshots of the split
table and market info table for a specified security for a 1 week period.
Market Data
|
Date |
OpenPrice |
HighPrice |
LowPrice |
ClosePrice |
Volume |
|
1/3/99 |
100 |
110 |
90 |
105 |
10000 |
|
1/4/99 |
105 |
110 |
80 |
100 |
20000 |
|
1/5/99 |
50 |
55 |
50 |
55 |
20000 |
|
1/6/99 |
55 |
65 |
55 |
60 |
30000 |
|
1/7/99 |
60 |
80 |
60 |
75 |
50000 |
|
1/10/99 |
25 |
30 |
20 |
26 |
100000 |
|
1/11/99 |
26 |
36 |
20 |
34 |
150000 |
Splits Events
|
Date |
SplitFactor |
Comments |
|
1/5/99 |
0.5 |
2 for 1 split |
|
1/10/99 |
0.3333 |
3 for 1 split |
Now the split-adjusted (or simply adjusted) prices and volumes for this
given period would be as given in the following table
|
Date |
OpenPrice |
HighPrice |
LowPrice |
ClosePrice |
Volume |
|
1/3/99 |
16.67 (=100*0.5*0.33) |
18.33 (=110*0.5*0.33) |
15 (=90*0.5*0.33) |
17.5 (=105*0.5*0.33) |
60,000 (=10,000*2*3) |
|
1/4/99 |
17.5 (=105*0.5*0.33) |
18.33 (=110*0.5*0.33) |
13.33 (=80*0.5*0.33) |
16.67 (=100*0.5*0.33) |
120,000
(=20,000*2*3)
|
|
1/5/99 |
16.67 (=50*0.33) |
18.33 (=55*0.33) |
16.67 (=50*0.33) |
18.33 (=55*0.33) |
60,000
(=20,000 * 3)
|
|
1/6/99 |
18.33
(=55*0.33)
|
21.67
(=65*0.33)
|
18.33
(=55*0.33)
|
20
(=60*0.33)
|
90,000
(=30,000 * 3)
|
|
1/7/99 |
20
(=60*0.33)
|
26.67
(=80*0.33)
|
20
(=60*0.33)
|
25
(=75*0.33)
|
150,000
(=50,000 * 3)
|
|
1/10/99 |
25 |
30 |
20 |
26 |
100,000 |
|
1/11/99 |
26 |
36 |
20 |
34 |
150,000 |
Volume-weighted price: This measure is a weighted average of the trade
prices where the size of each trade is used as the weight. The following
example illustrates the concept:
|
Tdate |
Time |
TradePrice |
TradeSize |
|
1/5/99 |
10:00a |
100 |
100 |
|
1/5/99 |
10:10a |
101 |
500 |
|
1/5/99 |
10:15a |
100.5 |
1000 |
|
1/5/99 |
10:20a |
99 |
200 |
|
1/5/99 |
10:25a |
98 |
300 |
|
1/5/99 |
10:30a |
100 |
400 |
|
1/5/99 |
10:35a |
99 |
500 |
|
1/5/99 |
10:45a |
98 |
600 |
|
1/5/99 |
10:55a |
99 |
700 |
Table A2.3
Now Volume Weighted Price (VWP) is defined as :

Therefore in the above example, the VWP for all trades
shown in the table is
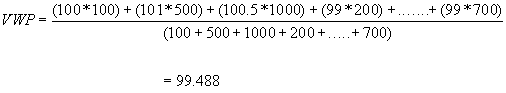
Standard Industry Code: Most market data vendors provide a categorization
of securities by the industry in which they operate. For example, IBM is
categorized to be in the "COMPUTERS" business. While typically they are codes,
in this benchmark we have expanded them in meaningful words.
Dividends & Yield: Dividends are pay-outs of earnings to shareholders.
They are specified as a dollar amount per share and the date of disbursement is
termed as the Ex-Dividend date. Dividends may be paid out per quarter or
annually or according to
any other schedule that the company chooses. Annual Yield for a
security, as defined for this benchmark, is the total dividend paid out during
a calendar year as a percentage of the average share price (split adjusted). It
is important to note that dividend payments should also be split adjusted
(dividend rate * split factor).
n-Day Moving Average: This is simple statistic wherein a n-day sliding
window is moved over the time period in question from the start date to the end
day. The average value (price) is calculate for each position of the window and
the calculated value is associated with the last date in the window. E.g
Consider the split adjusted prices in Table A2.3. The 3-day moving average for
the closing price would be as follows:
|
Date |
Moving Avg-ClosingPrice |
Comments |
|
1/5/99 |
17.5 |
Avg(17.5, 16,67, 18.33) |
|
1/6/99 |
18.33 |
Avg(16.67, 18.33, 20) |
|
1/7/99 |
21.11 |
Avg(18.33, 20, 25) |
|
1/10/99 |
23.67 |
Avg(20, 25, 26) |
|
1/11/99 |
28.33 |
Avg(25, 26, 34) |
Spread: is defined to be the difference between the price at which a broker
will sell a security and the price at which the broker will buy it. This is the
source of profits for a broker. Typically, large well recognized securities
have small spread while securities of small companies have larger spreads.
Coefficient of correlation for two sequences is defined as: the covariance
over the product of the standard deviations. If x and y are vectors, then the
covariance is covariance(x,y) = avg(x * y) - (avg(x)*avg(y)) correlation
coefficient = covariance(x * y) / (stddev(x)*stddev(y)) where avg is average,
stddev is the standard deviation.
The notions of ``specified period of x days'' or ``set of y securities''
are used in the query descriptions. To compute a specified period of x days
from a set of days D, choose x days without replacement randomly and uniformly
from D. If they must be consecutive days, then choose a single day randomly and
uniformly from the set of days that are at least x less than the most recent
day in the database. The same holds for hours in the tick database. To compute
a set of x securities from some set S, choose the x randomly and uniformly but
without replacement from S.
S&P/Russell indices. The composition of these indexes can be generated
by randomly selecting 500 and 2000 distinct securities at random uniformly
and without replacement from the
universe of securities.
Data Types. Data types for the data models described above are as
follows:
|
Data types |
Length |
|
Char |
Native implementation (usually 1 byte) |
|
Varchar(n) |
A variable length character array of max length 'n'
characters |
|
Long (integer) |
4 bytes |
|
Double (Floating point) |
Double Precision (8 bytes) |
|
Date |
Any representation of date large
enough to give precision up to (mmddyyyy) |
|
Time |
Any representation capable of precision up to
milliseconds |
Last updated April, 1999